Gradient Boosted Tree Regressor
A operação Gradient-Boosted Trees (GBT) para regressão possui como objetivo criar um modelo baseado em ensembles de Árvores de decisão. Para isso, GBT iterativamente treina (a partir de uma base de dados de entrada) um conjunto de árvores de decisão minimizando uma dada função de perda. A ideia do GBT é criar vários modelos (de árvore de decisão) considerados mais simples (ou fracos) a fim de criar um modelo mais poderoso e robusto, por combinar resultados desses vários modelos fracos.
Conectores
| Entrada | Saída |
|---|---|
| Dados utilizados para treinar o modelo | Dados de saída e modelo do algoritmo de regressão |
Tarefa
Nome da Tarefa
Aba Execução
| Parâmetro | Detalhe |
|---|---|
| Atributo(s) previsor(es) | Atributo que será usado para treinamento |
| Atributo com o rótulo | Atributo a ser predito |
| Atributos com a predição | Atributo contendo a predição do modelo |
| Iterações máximas | O número máximo de iterações do algoritmo boosting. O seu valor padrão é 100 |
| Regularização | Valor para regularizar o ajuste da função de perda do algoritmo. O seu valor padrão é 0.0 |
| Mix. para ElasticNet (entre 0 e 1) | Parâmetro de ajuste usado para a minimização da função objetivo usando uma combinação de L1 e L2. O seu valor por padrão é 0 |
| Profundidade máxima | Profundidade máxima permitida nas árvores de decisão |
| Instâncias mínimas | O número mínimo de instâncias (exemplos) que precisam estar em um nó folha de cada árvore |
| Ganho de informação mínimo | Mínimo de ganho de informação (information gain) para que haja a utilização de uma feature na divisão de um nó |
| Semente (seed) | Semente pseudo-aleatória para iniciar o modelo do GBT. |
| Métrica para validação cruzada | Define a métrica utilizada dentro da validação cruzada (se aplicável) para avaliar o modelo de classificação dentro das k partições |
| Atributo com o número da partição (fold) | Define o atributo a ter o número da partição para realizar uma validação cruzada (se aplicável) |
Exemplo de Utilização
Objetivo: Utilizar o modelo do Gradient Boosted Tree Regressor para predizer a qualidade de um vinho.
Base de Dados: Qualidade da Variante Vermelha do Vinho Verde Português
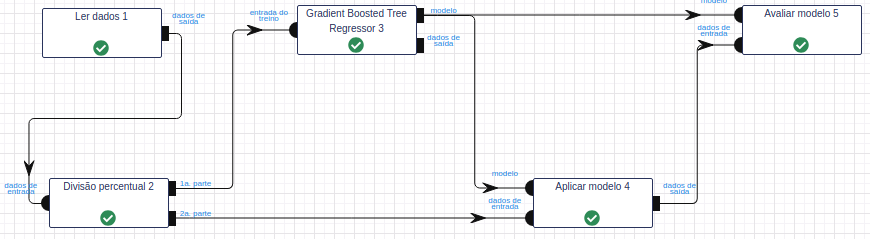
Leia a base de dados por meio da operação Ler dados.
Utilize a operação Divisão percentual para dividir a base de dados em treino e teste. No parâmetro Percentual, calibre-o utilizando 50% dos dados para treinar (1.ª parte) e 50% para testar (2.ª parte).
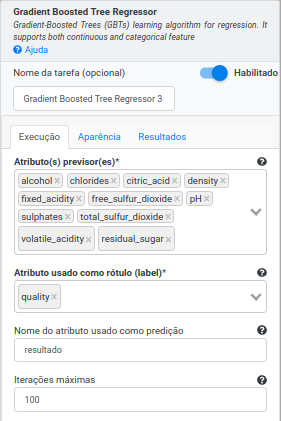
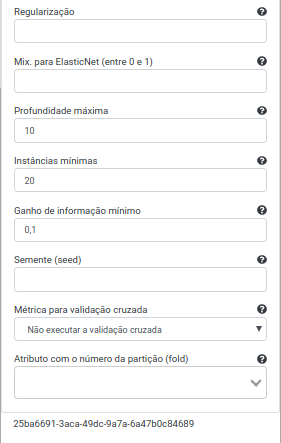
Na Operação Gradient Boosted Tree Regressor, selecione “alcohol”, “chlorides”, “citric_acid”, “density”, “fixed_acidity”, “free_sulfur_dioxide”, “pH”, “residual_sugar”, “sulphates”, “total_sulfur_dioxide” e “volatile_acidity” no campo Atributo(s) previsor(es). Selecione “quality” no campo Atributo com o rótulo e preencha “resultado” no campo Atributo com a predição (novo). Preencha 100 no campo Iterações máximas, 10 no campo Profundidade máxima, 20 no campo Número de instâncias e 0.1 no Ganho de informação. Deixe os demais parâmetros inalterados.
Na operação Aplicar Modelo, selecione “alcohol”, “chlorides”, “citric_acid”, “density”, “fixed_acidity”, “free_sulfur_dioxide”, “pH”, “residual_sugar”, “sulphates”, “total_sulfur_dioxide” e “volatile_acidity” no campo Atributo(s) previsor(es) e preencha “resultado” no campo Nome do novo atributo (herdado do modelo).
Na operação Avaliar Modelo, selecione “resultado” no campo Atributo usado para predição. Selecione “quality” no campo Atributo usado como label e a métrica “Raiz do erro quadrático médio” como Métrica para avaliação.
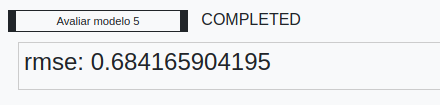
Execute o fluxo e visualize o resultado, que neste caso está de acordo com a raiz do erro quadrático médio (Root Mean Square Error ou RMSE):
Dúvidas e/ou sugestões envie um e-mail para suporte@lemonade.org.br