Perceptron multicamadas
O classificador Perceptron Multicamadas (Multi-Layer perceptron) baseia-se em abstrações de redes neurais encontradas no cérebro. Esse classificador cria um modelo com camadas de neurônios conectadas, considerando que cada camada possui diversos neurônios
Conectores
| Entrada | Saída |
|---|---|
| Dados utilizados para treinar o modelo | Dados de saída e modelo do algoritmo de classificação |
Tarefa
Nome da Tarefa
Aba Execução
| Parâmetro | Detalhe |
|---|---|
| Atributo(s) previsor(es) | Atributo(s) que será(ão) usado(s) para treinamento |
| Atributo com o rótulo | Atributo a ser classificado |
| Atributos com a predição (novo) | Atributo contendo a predição do modelo |
| Pesos | Pesos do algoritmo em um ensemble |
| Tamanho do bloco | Tamanho do bloco para empilhar os dados de entrada em matrizes para acelerar a computação. Os dados são empilhados por partições. Se o tamanho do bloco é maior que os dados restantes em uma partição, ele é ajustado ao tamanho desses dados. Tamanho recomendado é entre 10 e 1000. O seu valor padrão é 128 |
| Camada | Indica o número de camadas e a quantidade de neurônios por camada (de entrada, escondidas e de saída). Esses valores devem ser separados por vírgulas (e.g., “4,2,4” indica que existirá quatro neurônios na primeira camada, dois na camada escondida, e quatro na camada de saída). Obrigatoriamente, a primeira e última camada devem conter um número de neurônios igual ao número de atributos da base de dados |
| Iterações máximas | Determina o número máximo de iterações a serem realizadas durante o treinamento do modelo, a fim de limitar um treinamento excessivo resultando em pouca generalização do modelo |
| Semente | Semente usada para a geração de números aleatórios durante a inicialização do modelo |
| Solucionador | Solucionador a ser utilizado pelo modelo para otimização. As opções são gd (minibatch gradient descent) e l-bfgs |
| Métrica para validação cruzada | Define a métrica utilizada dentro da validação cruzada (se aplicável) para avaliar o modelo de classificação dentro das k partições |
| Atributo com o número da partição (fold) | Define o atributo a ter o número da partição para realizar uma validação cruzada (se aplicável) |
| Usar classificação um-contra-todos (one-vs-rest) | Se selecionado, o algoritmo realizará classificação um-contra-todos ao invés de classificação tradicional (neste caso, binária ou multi-classe) |
Definições
Camada
Esse classificador utiliza a função (de ativação) logística nos neurônios em camadas comuns (intermediárias) e a função softmax nos neurônios na camada de saída.
Exemplo de Utilização
Objetivo: Utilizar o modelo do Perceptron Multicamadas para classificar a espécie da planta Íris.
Base de Dados: Íris
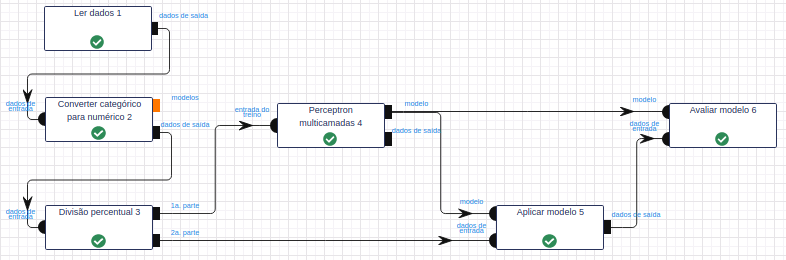
Leia a base de dados Irís por meio da operação Ler dados.
Utilize a operação Converter categórico para numérico para converter os valores do atributo classe em valores numéricos. Para isso, utilize “class” no campo Atributos, String como Tipo de indexador e “class_index” como Nome para novo(s) atributos indexados.
Utilize a operação Divisão percentual para dividir a base de dados em treino e teste. No parâmetro Pesos, calibre-o utilizando 50% dos dados para treinar e 50% para testar.
Na operação Perceptron Multicamadas, selecione “petal_length”, “petal_width”, “sepal_length” e “sepal_width” no campo Atributo(s) previsor(es). Selecione “class_index” no campo Atributo com o rótulo e preencha ‘resultado’ no campo Atributo com a predição (novo). Além disso, indique que será utilizada uma camada de entrada, uma escondida e uma de saída, preenchendo Camadas com “4,20,4”. Isso indicará que irão existir quatro neurônios na primeira camada (iguais aos números de atributos da base Íris), 20 na camada escondida, e quatro na de saída (também iguais aos números de atributos da base Íris). Deixe os demais parâmetros inalterados.
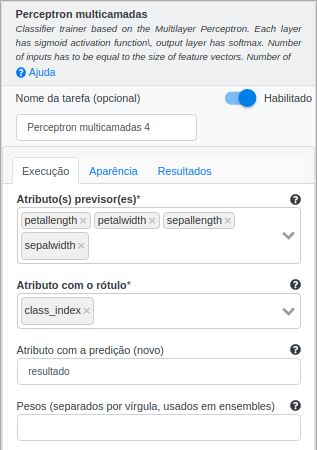
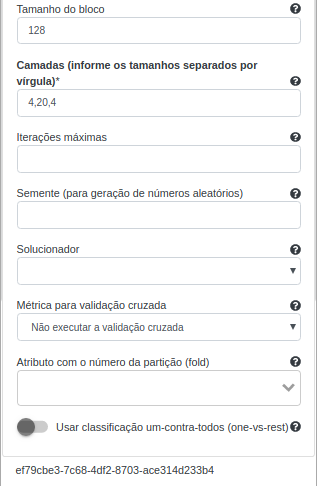
Na operação Aplicar Modelo, selecione “petal_length”, “petal_width”, “sepal_length” e “sepal_width” no campo Atributo(s) previsor(es) e preencha “resultado” no campo Nome do novo atributo.
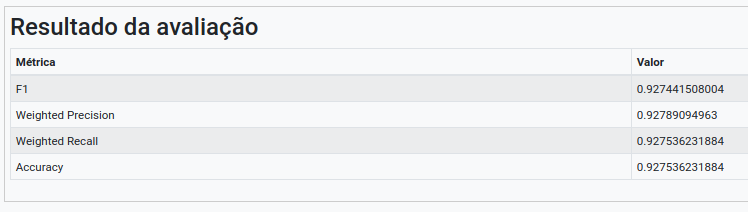
Na operação Avaliar Modelo, selecione “resultado” no campo Atributo usado para predição. Selecione “class_index” no campo Atributo usado como label e a métrica “F1” como Métrica para avaliação.
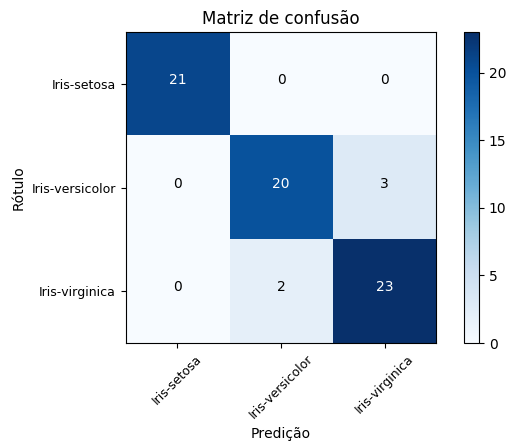
Execute o fluxo e visualize o resultado, i.e., a matriz de confusão gerada para as predições do modelo de árvore de decisão e, consequentemente, a tabela representando as métricas de classificação (derivadas da matriz de confusão).
Dúvidas e/ou sugestões envie um e-mail para suporte@lemonade.org.br