K-Means
Método de clusterização k-means.
Conectores
| Entrada | Saída |
|---|---|
| Dados utilizados para treinar o modelo | Dados de saída e Modelo do algoritmo de agrupamento |
Tarefa
Nome da Tarefa
Aba Execução
| Parâmetro | Detalhe |
|---|---|
| Quantidade de agrupamentos (K) | Número de clusters a serem formados tal como a quantidade de centróides |
| Tolerância | Tolerância relativa para declarar convergência do algoritmo |
| Tipo | Tipo de k-means a ser utilizado |
| Geração dos centróides iniciais | Estratégia a ser utilizada para gerar os centróides iniciais |
| Número máx. de iterações | Quantidade máxima de iterações |
| Atributo(s) previsor(es) | Atributos a ser utilizado para clusterizar as amostras do conjunto de dados |
| Atributos com a Predição (novo) | Nome do novo atributo atribuído criado pelo algoritmo de agrupamento especificado |
| Métrica para validação cruzada | |
| Atributo com o número da partição (fold) |
Definições
Tipo
Tipos de k-means:
- Tradicional: Frequentemente utilizado para agrupar amostras do conjunto de dados em uma quantidade pré-especificada de grupos.
- Bisecting K-Means: Bisecting k-means difere-se do K-means tradicional por ser um agrupamento hierárquico.
Geração dos Centróides Iniciais
Tipos:
- K-Means || K-Means ++ variant: Versão paralelizada do K-means++ para inicialização dos centróides iniciais. Os centróides iniciais gerados pelo K-means++ possuem uma garantia de aproximação da solução ótima.
- Aleatório: Inicialização aleatória dos centróides.
Exemplo de Utilização
Objetivo: Utilizar o k-means para agrupar as espécies da Íris.
Base de Dados: Íris

Adicione uma base de dados por meio da operação Ler dados.
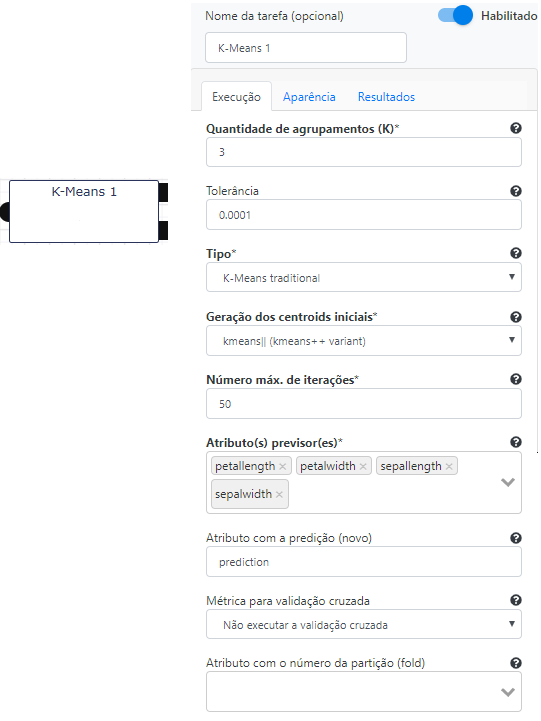
Na operação K-means, preencha 3 no campo Quantidade de agrupamentos(k), 0.0001 no campo Tolerância, “k-Means tradicional” no campo Tipo, “K-Means || K-Means ++ variant” no campo Geração de centróides iniciais e 50 no campo Número max. de interações. Selecione “petal_length”, “petal_width”, “sepal_length” e “sepal_width” como Atributo(s) previsor(es) e “prediction” como Atributo com a predição (novo).
Na operação Tabela, não preencha nada.
Execute o fluxo e visualize o resultado.
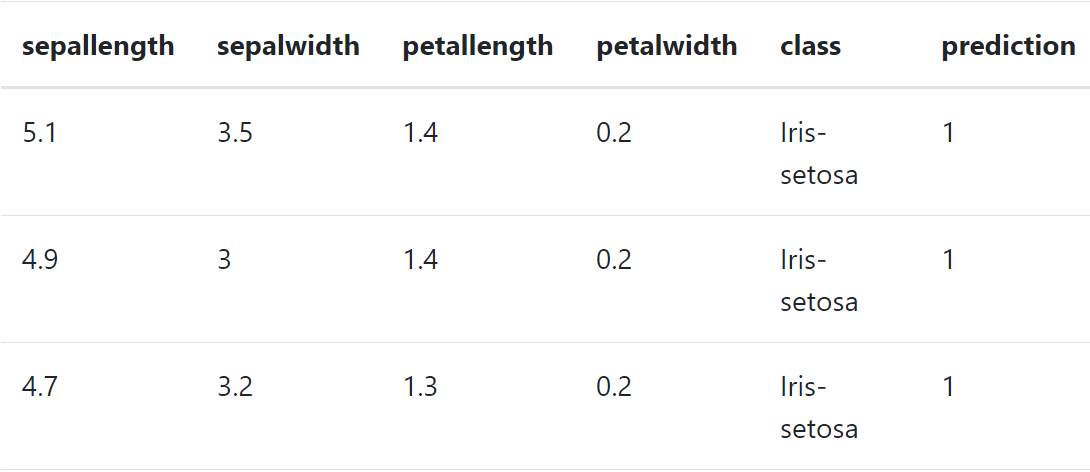
Com a execução do modelo a predição de cada um dos três clusteres pode ser obtido visualizando o resultado apresentado pela tabela de visualização.
Dúvidas e/ou sugestões envie um e-mail para suporte@lemonade.org.br