Regressão Logística
O objetivo da operação Regressão Logística é similar ao da operação Regressão Linear, i.e., produzir um modelo linear que permite estimar a probabilidade associada à ocorrência de um dado exemplo pertencer a uma classe (e.g., positiva ou negativa) dado um conjunto de atributos preditivos. Contudo, diferentemente do modelo produzido pela Regressão Linear, o modelo logístico possui uma variável resposta (i.e., o atributo classe) categórica - usualmente binária - ao invés de uma variável resposta real.
Conectores
| Entrada | Saída |
|---|---|
| Dados utilizados para treinar o modelo | Dados de saída e modelo do algoritmo de classificação |
Tarefa
Nome da Tarefa
Aba Execução
| Parâmetro | Detalhe |
|---|---|
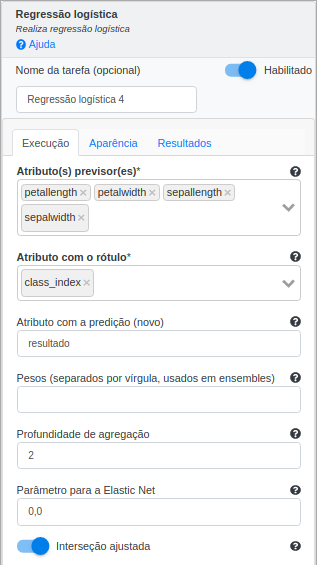
| Atributo(s) previsor(es) | Atributo(s) que será(ão) usado(s) para treinamento |
| Atributo com o rótulo | Atributo a ser classificado |
| Atributos com a predição | Atributo contendo a predição do modelo |
| Pesos | Pesos do algoritmo em um ensemble |
| Profundidade de agregação | Define o valor de profundidade para a agregação por árvore do algoritmo. Deve ser maior ou igual a 2. O valor padrão deste parâmetro é igual a 2 |
| Parâmetro para Elastic Net | Parâmetro de ajuste usado para a minimização da função objetivo usando uma combinação de L1 e L2. O valor padrão deste parâmetro é 0 |
| Interseção ajustada | Define se o modelo deve incluir o intercept |
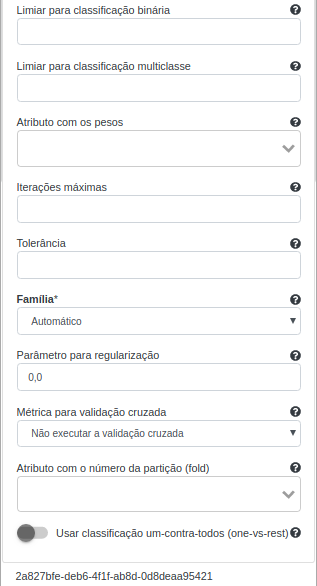
| Limiar para classificação binária | Limiar usado na definição da classe que será escolhida |
| Limiar para classificação multiclasse | Limiares usados no ajuste da probabilidade de cada uma das classes |
| Atributo com os pesos | Atributos passados ao modelo que terão um peso diferenciado |
| Interações máximas | Define o número máximo de iterações para a convergência do algoritmo. O valor padrão deste parâmetro é 100 |
| Tolerância | Tolerância de convergência para algoritmos iterativos (>=0.0) |
| Família | Família do algoritmo que será usado na criação do modelo. Pode assumir os seguintes valores: “Binomial”, “Multinomial” ou “Automática” |
| Parâmetro para regularização | Valor para regularizar o fitting da função de perda do algoritmo, esse parâmetro é usado para evitar overfitting. O valor deste parâmetro é 0.0 |
| Métrica para validação cruzada | Define a métrica utilizada dentro da validação cruzada (se aplicável) para avaliar o modelo de classificação dentro das k partições |
| Atributo com o número da partição (fold) | Define o atributo a ter o número da partição para realizar uma validação cruzada (se aplicável) |
| Usar classificação um-contra-todos (one-vs-rest) | Se selecionado, o algoritmo realizará classificação um-contra-todos ao invés de classificação tradicional (neste caso, binária ou multi-classe) |
Definições
Família
Existem as seguintes famílias de algoritmos:
- Binomial: Usa uma regressão logística binomial para realizar previsões binárias. É válida somente para problemas de classificação binária (i.e., com apenas duas classes).
- Multinomial: Usa uma regressão logística multinomial para realizar predições em problemas de classificação multi-classe (i.e., com mais de duas classes).
- Automático: A plataforma vai inferir qual das variantes acima será utilizada.
Exemplo de Utilização
Objetivo: Utilizar o modelo de Regressão Logística para classificar a espécie da planta Íris
Base de Dados: Íris
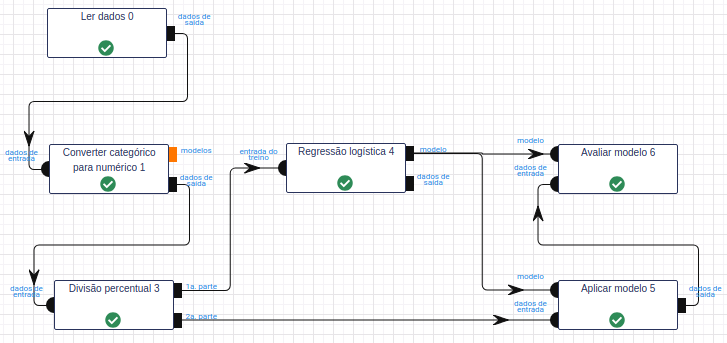
Leia a base de dados Irís por meio da operação Ler dados.
Utilize a operação Converter categórico para numérico para converter os valores do atributo classe em valores numéricos. Para isso, utilize “class” no campo Atributos, String como Tipo de indexador e “class_index” como Nome para novo(s) atributos indexados.
Utilize a operação Divisão percentual para dividir a base de dados em treino e teste. No parâmetro Percentual, calibre-o utilizando 50% dos dados para treinar (1ª parte) e 50% para testar (2ª parte).
Na operação Regressão Logística, selecione “petal_length”, “petal_width”, “sepal_length” e “sepal_width” no campo Atributo(s) previsor(es). Selecione “class_index” no campo Atributo com o rótulo e preencha “resultado” no campo Atributo com a predição (novo). Além disso, escolha a Família “Automático”, para selecionar o tipo de família (binomial ou multinomial) automaticamente. Deixe os demais parâmetros inalterados.
Na operação Aplicar Modelo, selecione “petal_length”, “petal_width”, “sepal_length” e “sepal_width” no campo Atributo(s) previsor(es) e preencha “resultado” no campo Nome do novo atributo (herdado do modelo).
Na operação Avaliar Modelo, selecione “resultado” no campo Atributo usado para predição. Selecione “class_index” no campo Atributo usado como label e a métrica “F1” como Métrica para avaliação.
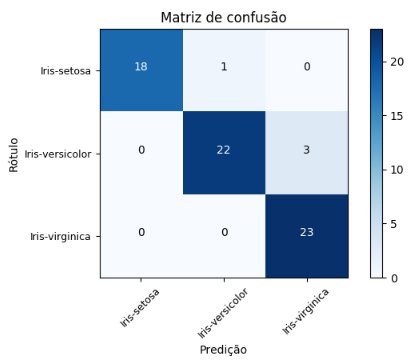
Execute o fluxo e visualize o resultado, i.e., a matriz de confusão gerada para as predições do modelo de árvore de decisão e, consequentemente, a tabela representando as métricas de classificação (derivadas da matriz de confusão).

Dúvidas e/ou sugestões envie um e-mail para suporte@lemonade.org.br