Random Forest
Random Forest (floresta aleatória) é uma generalização da operação Árvore de Decisão, em que se utiliza um conjunto de árvores de decisão (aleatórias) a fim de minimizar o sobreajuste (overfitting) de cada modelo individual de árvore gerado para os dados de entrada.
Conectores
| Entrada | Saída |
|---|---|
| Dados utilizados para treinar o modelo | Dados de saída e modelo do algoritmo de classificação |
Tarefa
Nome da Tarefa
Aba Execução
| Parâmetro | Detalhe |
|---|---|
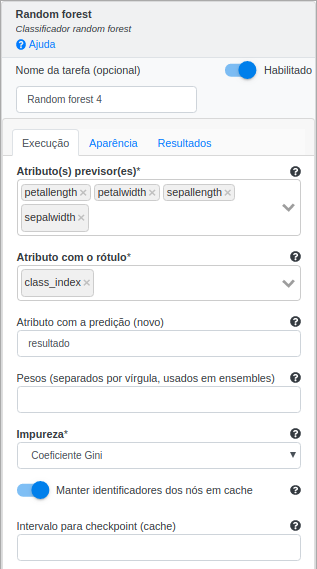
| Atributo(s) previsor(es) | Atributo(s) que será(ão) usado(s) para treinamento |
| Atributo com o rótulo | Atributo a ser classificado |
| Atributos com a predição (novo) | Atributo contendo a predição do modelo |
| Pesos | Pesos do algoritmo em um ensemble |
| Impureza | Medida para quantificar a impureza de cada nó de modo a realizar as divisões das árvores |
| Manter identificadores dos nós em cache | Se selecionado, o algoritmo evita passar o modelo atual para os executores da próxima iteração |
| Intervalo para checkpoint (cache) | Frequência com a qual fazer checkpoints |
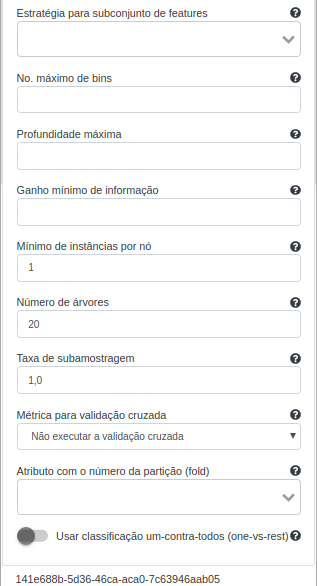
| Estratégia para subconjunto de features | Define o cálculo usado para definir a quantidade de atributos que será passado para cada árvore |
| No. máximo de bins | Número de bins utilizados para discretizar uma variável contínua |
| Profundidade máxima | Profundidade máxima permitida nas árvores de decisão |
| Ganho mínimo de informação | Mínimo de information gain para que haja a utilização de uma feature na divisão de um nó |
| Mínimo de instâncias por nó | O número mínimo de instâncias que precisam estar em um nó folha de cada árvore. O seu valor padrão é 1 |
| Número de árvores | O número de árvores na floresta. O seu valor padrão é 20 |
| Taxa de subamostragem | Fração do conjunto de dados que será passado para cada árvore. O seu valor padrão é 1,0 |
| Métrica para validação cruzada | Define a métrica utilizada dentro da validação cruzada (se aplicável) para avaliar o modelo de classificação dentro das k partições |
| Atributo com o número da partição (fold) | Define o atributo a ter o número da partição para realizar uma validação cruzada (se aplicável) |
| Usar classificação um-contra-todos (one-vs-rest) | Se selecionado, o algoritmo realizará classificação um-contra-todos ao invés de classificação tradicional (neste caso, binária ou multi-classe) |
Definições
Impureza
Tipos de impureza:
Coeficiente Gini: É uma métrica de desigualdade que varia entre zero e um. O coeficiente Gini dita que se selecionarmos aleatoriamente uma amostra arbitrária da base de dados e essa amostra sempre conter exemplos da mesma classe, isso significa que a amostra de dados é dita como pura, resultando em um coeficiente de Gini igual a um. Caso contrário, a amostra de dados é dita como impura, resultando em um coeficiente de Gini igual a zero.
Entropia: É uma medida de teoria da informação que calcula o grau de desorganização em um sistema. Também é utilizada para caracterizar a (im)pureza de uma amostra de dados. Se a amostra for completamente homogênea/pura (i.e., todos os exemplos estiverem na mesma classe), então a entropia é zero. Se a amostra for dividida em partes iguais (por exemplo, classe positiva com 50% dos exemplos e classe negativa com os 50% restantes dos exemplos), então terá entropia de um, caracterizando uma amostra impura/não-homogênea.
Estratégia para subconjunto de features
Tipos de estratégia:
- Auto: A própria aplicação analisa os dados e escolhe o melhor subconjunto de features.
- All: Todas os atributos serão utilizados por cada árvore.
- One third: Cada árvore irá receber um subconjunto com $\dfrac{n}{3}$, em que n representa a quantidade 1. total de atributos.
- SQRT: Cada árvore irá receber um subconjunto com $\sqrt{n}$, em que $n$ representa a quantidade total de atributos.
- Log2: Cada árvore irá receber um subconjunto com $\log_{2}n$, em que n representa a quantidade total de atributos.
- (0.0-1.0]: Porcentagem de atributos que serão utilizados em cada árvore.
- [1-n]: Um valor entre 1 e n de atributos serão utilizados por cada árvore, em que n é o número total de atributos escolhidos para cada árvore.
$\sqrt{5}$
Exemplo de Utilização
Objetivo: Utilizar o modelo do Random Forest para classificar a espécie da planta Íris.
Base de Dados: Íris
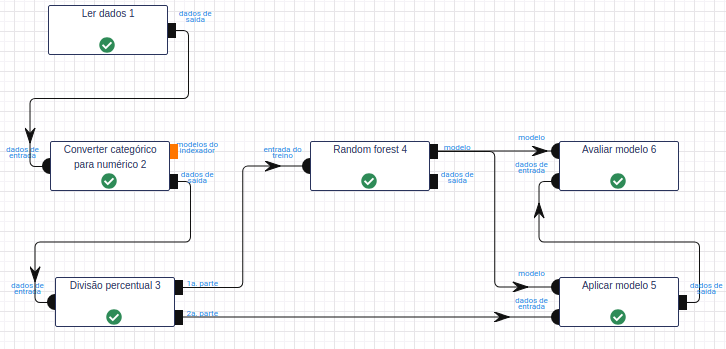
Leia a base de dados Irís por meio da operação Ler dados.
Utilize a operação Converter categórico para numérico para converter os valores do atributo classe em valores numéricos. Para isso, utilize “class” no campo Atributos, String como Tipo de indexador e “class_index” como Nome para novo(s) atributos indexados.
Utilize a operação Divisão percentual para dividir a base de dados em treino e teste. No parâmetro Percentual, calibre-o utilizando 50% dos dados para treinar (1.ª parte) e 50% para testar (2.ª parte).
Na operação Random Forest, selecione “petal_length”, “petal_width”, “sepal_length” e “sepal_width” no campo Atributo(s) previsor(es). Selecione “class_index” no campo Atributo com o rótulo e preencha “resultado” no campo Atributo com a predição (novo). Deixe os demais parâmetros inalterados.
Na operação Aplicar Modelo, selecione “petal_length”, “petal_width”, “sepal_length” e “sepal_width” no campo Atributo(s) previsor(es) e preencha “resultado” no campo Nome do novo atributo (herdado do modelo).
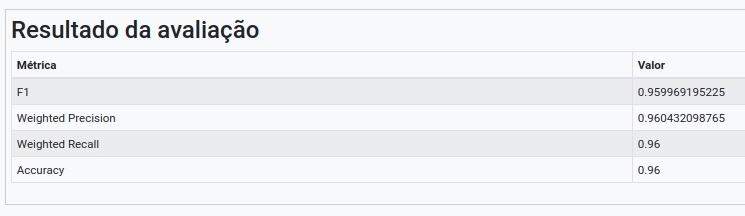
Na operação Avaliar Modelo, selecione “resultado” no campo Atributo usado para predição. Selecione “class_index” no campo Atributo usado como label e a métrica “F1” como Métrica para avaliação.
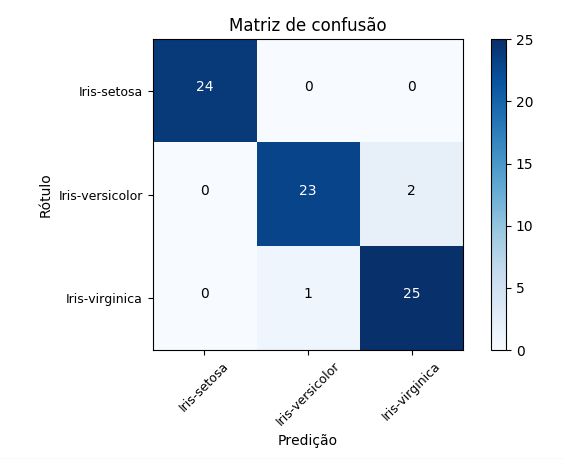
Execute o fluxo e visualize o resultado, i.e., a matriz de confusão gerada para as predições do modelo de árvore de decisão e, consequentemente, a tabela representando as métricas de classificação (derivadas da matriz de confusão).
Dúvidas e/ou sugestões envie um e-mail para suporte@lemonade.org.br