Escalador Padrão (Z-score)
O objetivo desse escalador é fazer com que cada atributo individualmente se pareça com uma distribuição normal padrão de forma aproximada, e.g., Gaussiana com média 0 e variância unitária.
Conectores
| Entrada | Saída |
|---|---|
| Dados a serem tratados | Dados tratados e modelo de transformação |
Tarefa
Nome da Tarefa
Aba Execução
| Parâmetro | Detalhe |
|---|---|
| Atributo com as características (features) | Atributo que será transformado pelo escalador |
| Nome do novo atributo | Nome que o atributo escalado receberá |
| Centralizar os dados com a média | Centraliza os dados com a média antes de escalar. Não recomendado para conjuntos de dados esparsos |
| Escalar os dados para o desvio padrão unitário | Escala os dados para terem desvio padrão unitário |
Exemplos de Utilização
Exemplo 1
Objetivo: Remover linhas duplicadas da base de dados.
Base de Dados: Íris

Adicione uma base de dados por meio da operação Ler dados.
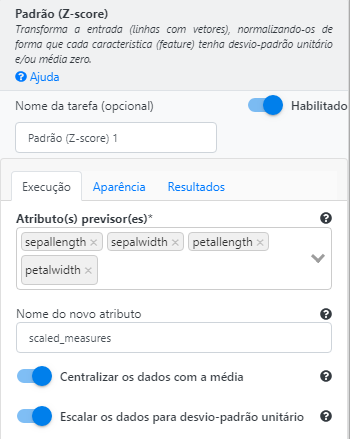
Utilize a operação Z-score para escalar os atributos. Selecione “sepallength”, “sepalwidth”, “petallength” e “petalwidth” no campo Atributo(s) previsor(es). Preencha “scaled_measures” no campo Nome do novo atributo.
Adicione a visualização em Tabela para ver os resultados.
Execute o fluxo e visualize o resultado.
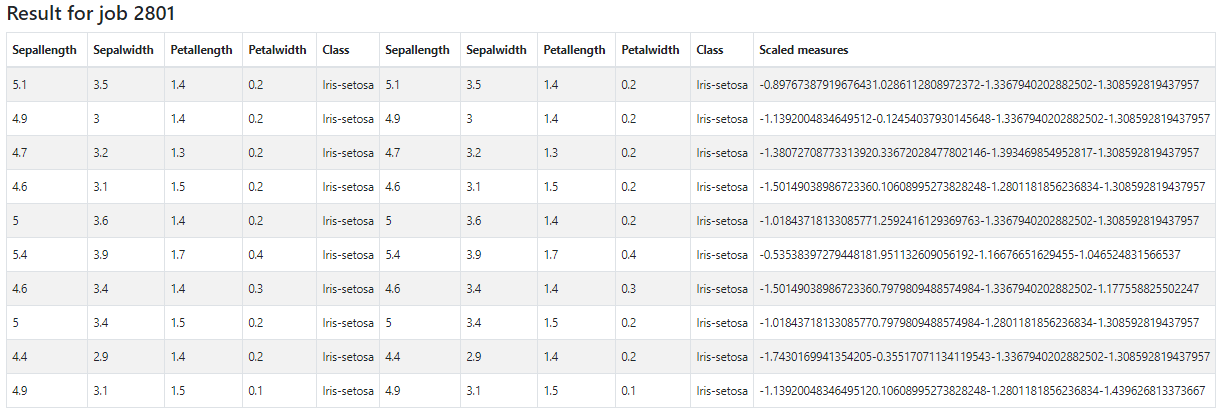
O resultado possui o atributo “scaled_measures”, que é um vetor de quatro elementos, correspondente aos atributos numéricos da base já escalados.
Exemplo 2 - Reutilização do modelo
Objetivo: A reutilização do modelo aprendido pelo escalador pode ser útil, por exemplo, ao processar o dado em batches. O segundo batch pode ser escalado de acordo com o primeiro, o que pode acontecer com a divisão de dados entre treino e teste numa tarefa de aprendizado supervisionado. Abaixo, é apresentado um exemplo do uso do Z-score com a reutilização do modelo.
Base de Dados: Íris
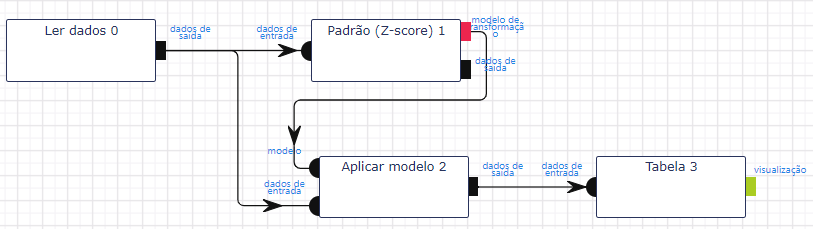
Adicione uma base de dados por meio da operação Ler dados.
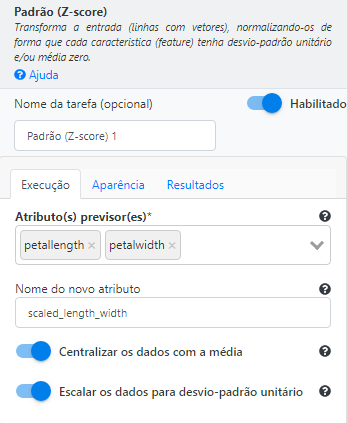
Adicione e utilize a operação Z-score para escalar os atributos. Selecione “petallength” e “petalwidth” no campo Atributo(s) previsor(es). Preencha “scaled_length_width” no campo Nome do novo atributo.
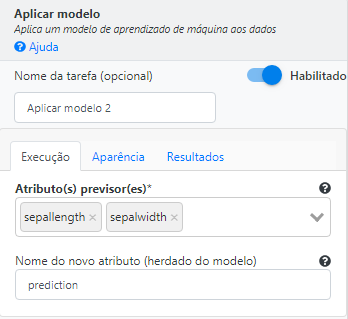
Utilize a operação Aplicar modelo. Selecione “sepallength” e “sepalwidth” no campo Atributos previsores. Preencha “prediction” no campo Nome do novo atributo.
Adicione a visualização em Tabela para ver os resultados.
Execute o fluxo e observe o resultado.
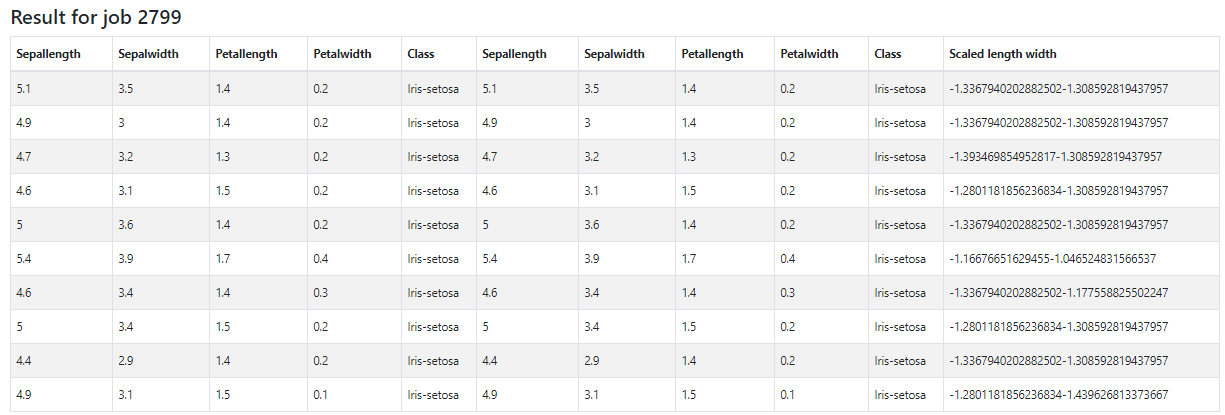
O resultado possui o atributo “scaled_length_width”, que é um vetor de dois elementos, correspondente aos atributos “sepal length” e “sepal width” escalados de acordo com o modelo aprendido com os atributos “petallength” e “petalwidth”. É possível notar a diferença entre ajustar e aplicar o modelo nos mesmos dados, que resultou nas duas primeiras posições do vetor do caso de uso anterior, e ajustar o modelo e aplicar em dados diferentes. Como a média e o desvio padrão para os atributos “petallength” e “petalwidth” são menores, e esses foram os parâmetros aprendidos pelo escalador, os dados dessa vez acabaram positivos, ao contrário do resultado anterior.
Dúvidas e/ou sugestões envie um e-mail para suporte@lemonade.org.br