Processar Tópicos
Operação que descreve os tópicos encontrados pelo método de clusterização LDA pelos seus termos com maiores pesos. Cada tópico encontrado pelo LDA possui uma distribuição sobre os termos do dicionário, os termos com maiores pesos são os mais relevantes para discriminar o tópico.
Conectores
| Entrada | Saída |
|---|---|
| Dados de Entrada, Modelo e Vocabulário utilizados para analisar a clusterização LDA | Para cada tópico retorna os seus termos mais importantes e seus respectivos pesos |
Tarefa
Nome da Tarefa
Aba Execução
| Parâmetro | Detalhe |
|---|---|
| Termos por tópico (max) | Quantidade máxima de termos a serem selecionados por tópico |
Exemplo de Utilização
Objetivo: utilizar o processamento de tópicos para descrever os tópicos encontrados pelo LDA.
Base de Dados: Sentiment Labelled Sentences
Adicione uma base de dados por meio da operação Ler dados.
Na operação Amostrar selecione as 200 primeiras amostras do dataset para criar o modelo LDA.
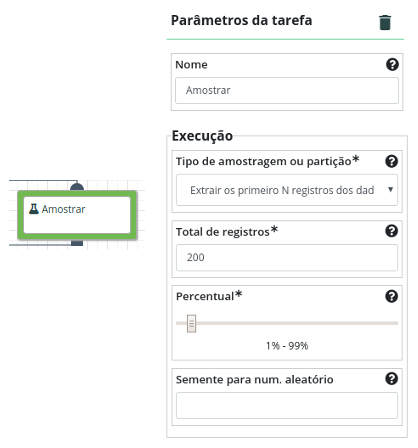
Utilize a operação Transformar para remover pontuação, acentuação e colocar todas as palavras em minúsculo. Criando um novo atributo lowered_text o qual possui o texto original transformado.
Utilize a operação Dividir Texto separe o texto em tokens utilizando espaço como delimitador, utilizando “Simples, use espaços como delimitado” no campo Tipo. Preencha o campo Atributos com “lowered_text” e o campo Nome do novo atributo com “text_tokens”. Coloque 2 no campo Tamanho Mínimo de Tokens.
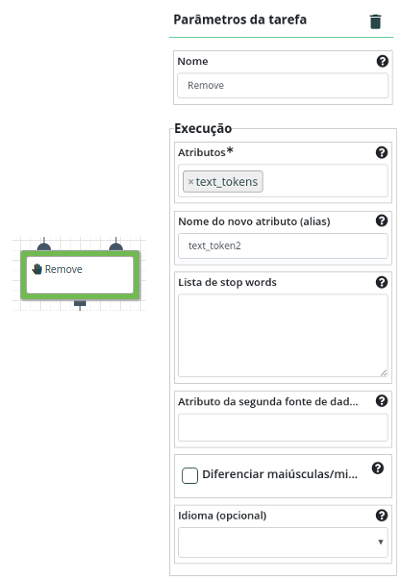
Remova as stopwords. Para isso, carregue o arquivo com a definição das stopwords utilizando a operação Ler Dados. Utilize o operador Remover palavras comum, selecione “text_tokens” como Atributos e “text_token2” como Nome do novo Atributo que irá conter o texto sem as stopwords.
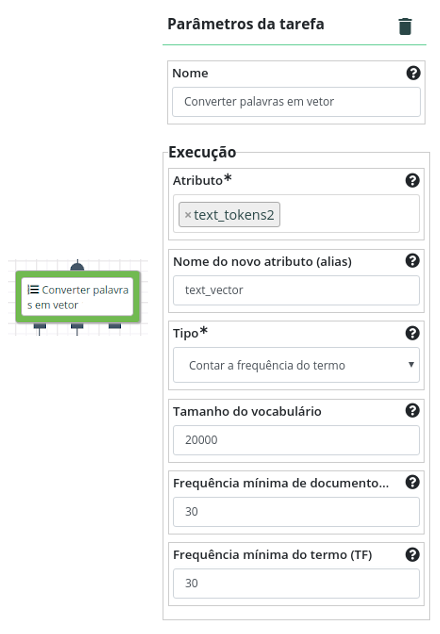
Utilize a operação Converter Palavras em Vetores e crie um vetor com a frequência de cada termo usando TF-IDF. Selecione “text_tokens2” como Atributo, “text_vector” como Nome do novo atributo, “Contar a frequência do termo” como Tipo, 20000 como Tamanho do vocabulário, e 30 como Frequência mínima de documento e Frequência Mínima do Termo.
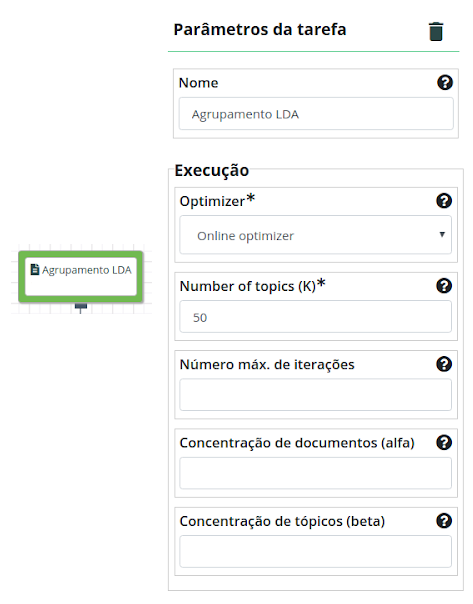
Na operação Agrupamento LDA, selecione o Online Variational Bayes como otimizador e uma quantidade máxima de 50 tópicos. Selecione o vetor “text_vector” para os Atributos a serem usados e preencha “topics” no campo Atributo com a predição.
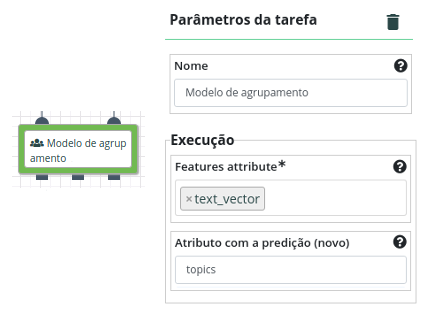
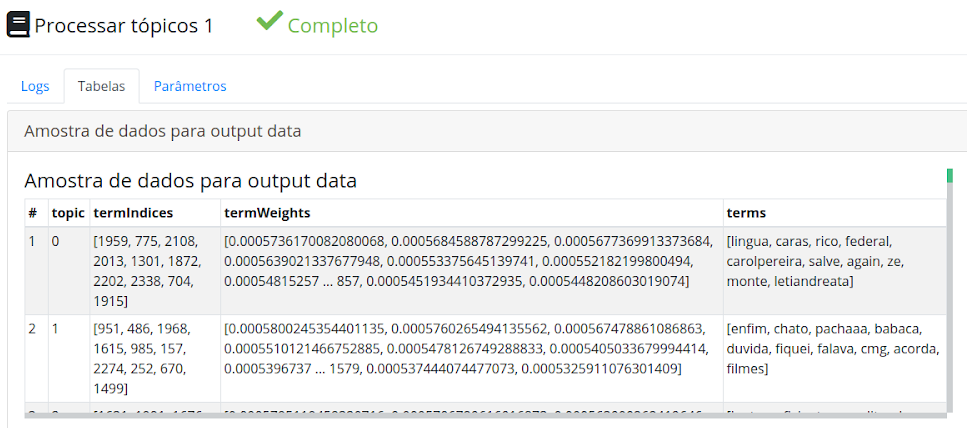
Execute e visualize as tarefas descritas acima, os termos com maiores pesos de cada tópico são obtidos pelo processamento de tópicos.
Link vem pra cá
Dúvidas e/ou sugestões envie um e-mail para suporte@lemonade.org.br