Hash sensível à localidade (LSH)
A operação Hash sensível à localidade (Locality-sensitive hashing ou LSH) aplica funções hash sobre um conjunto de atributos e produz um novo atributo, que é um vetor dos códigos hash da instância para cada uma das funções aplicadas. O objetivo ao aplicar essa operação é que instâncias muito similares terminem com alta probabilidade de ter o mesmo código hash, reduzindo-se assim a dimensionalidade da base de dados de entrada.
Conectores
| Entrada | Saída |
|---|---|
| Dados a serem tratados | Dados tratados |
Tarefa
Nome da Tarefa
Aba Execução
| Parâmetro | Detalhe |
|---|---|
| Número de tabelas hash | Número de funções hash que serão aplicadas no(s) atributo(s) |
| Atributo(s) previsor(es) | Atributos da base de dados que sofrerão pré-processamento |
| Atributo para saída | Atributo que terá a saída da operação |
| Tipo do LSH | Tipo de LSH: “Min Hash LSH para distância de Jaccard” (Min Hash LSH for Jaccard distance) ou “Projeção aleatória em buckets para distância euclidiana” (Bucketed Random Projection LSH) |
| Tamanho do bucket (apenas para Bucketed Random Projection LSH) | Comprimento de cada bucket, onde as instâncias que caem no mesmo bucket recebem o mesmo código hash |
| Semente para números aleatórios | Semente usada para gerar as funções hash de forma reprodutível |
Definições
Tipo do LSH
Existem os seguintes tipos do LSH
Min Hash LSH para distância de Jaccard:
Sejam a e b duas instâncias quaisquer. A similaridade de Jaccard entre elas é dada por:
interseção(a, b) / união(a, b)
onde a interseção e a união são obtidas comparando os elementos das instâncias na devida ordem. No hash mínimo para distância de Jaccard, para cada instância é produzido um código hash para cada elemento nela e é mantido o menor desses códigos. Assim, a probabilidade de que o hash de a e de b sejam iguais é igual à similaridade de Jaccard. A distância de Jaccard é dada apenas por 1 - similaridade de Jaccard.Projeção aleatória em buckets para distância euclidiana:
Na projeção aleatória por buckets para distância Euclidiana, o código hash é obtido projetando-se o vetor de atributos em um vetor aleatório unitário, e dividindo-se esse resultado pelo comprimento do bucket. Assim, quanto menor o comprimento dos buckets, menor é a probabilidade de se obter instâncias não similares entre si mapeadas para o mesmo bucket, ou seja, com o mesmo código hash. No entanto, diminuindo-se demais esse comprimento, é possível que instâncias similares acabem em buckets diferentes.
Exemplo de Utilização
Objetivo: Utilizar a operação Hashing sensível a contexto para reduzir a dimensionalidade da base de dados Diabetes.
Base de Dados: Pima Indians Diabetes

Leia abase de dados por meio da operação Ler dados
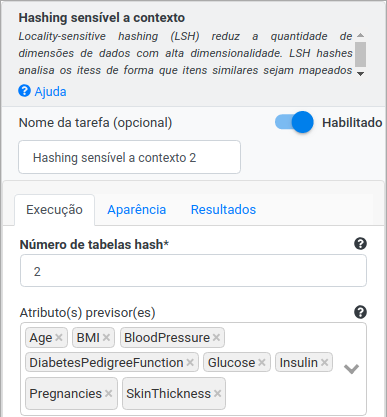
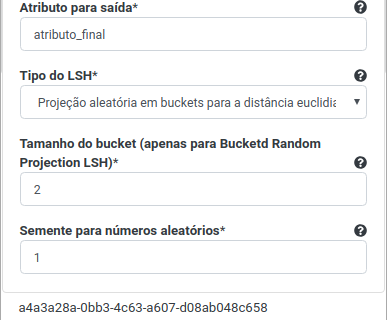
Na operação Hashing sensível a contexto, preencha 2 no campo Número de tabelas hash. Selecione “Age”, “BMI”, “BloodPressure”, “DiabetesPedigreeFunction”, “Glucose”, “Insulin”, “Pregnancies” e “SkinThickness” no campo Atributo(s) previsor(es). Preencha “atributo_final” no campo Atributo para saída. Selecione “Projeção aleatória em buckets para distância euclidiana” no campo Tipo LSH e preencha 2 no campo Tamanho do bucket e 1 no campo Semente para números aleatórios.
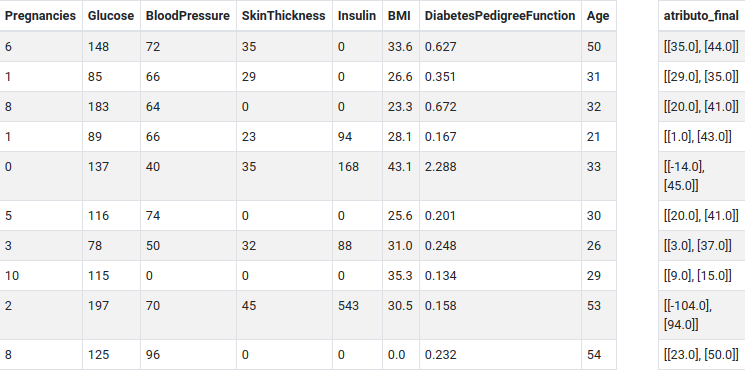
Execute o fluxo e visualize uma amostra dos resultados do LSH. Abaixo é mostrada as 10 primeiras instâncias da base de dados com os atributos originais “Age”, “BMI”, “BloodPressure”, “DiabetesPedigreeFunction”, “Glucose”, “Insulin”, “Pregnancies” e “SkinThickness” e o atributo de saída do LSH, i.e., o “atributo final”. Observe que os 8 atributos originais da base de dados foram transformados em um atributo que é uma estrutura vetorial com 2 tabelas hash.
Dúvidas e/ou sugestões envie um e-mail para suporte@lemonade.org.br