Latent Dirichlet Allocation (LDA)
Método de clusterização não supervisionada de documentos em tópicos.
Conectores
| Entrada | Saída |
|---|---|
| Dados utilizados para treinar o modelo | Dados de saída e Modelo do algoritmo de agrupamento |
Tarefa
Nome da Tarefa
Aba Execução
| Parâmetro | Detalhe |
|---|---|
| Atributo(s) previsor(es) | Atributo que será usado para treinamento |
| Atributos com a Predição (novo) | |
| Otimizador | Otimizador a ser utilizado para aprender o modelo. |
| Número de Tópicos (K) | |
| Número máximo de iterações | |
| Concentração de documentos (alfa) | Parâmetro alpha da distribuição de Dirichlet, o qual controla a priori a distribuição de documentos sobre os tópicos |
| Concentração de tópicos (beta) | Parâmetro beta da distribuição de Dirichlet, o qual controla a priori a distribuição de tópicos sobre os termos |
| Métrica para validação cruzada | |
| Atributo com o número da partição (fold) |
Definições
Tipos de Optimizer
Otimizador EM (Expectation Maximization): utiliza o método Expectation Maximization na função de verossimilhança para estimar os parâmetros.
Otimizador Online: utiliza inferência variacional online para a estimativa dos parâmetros. A cada iteração um subconjunto do corpus é processado e a distribuição de termos por tópicos são atualizadas.
Exemplo de Utilização
Objetivo: utilizar o método de clusterização LDA para encontrar tópicos em comentários de filmes.
Base de Dados: Sentiment Labelled Sentences
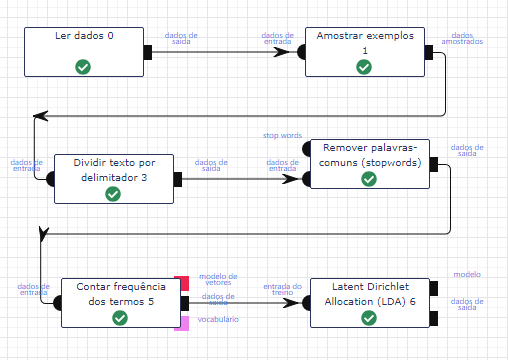
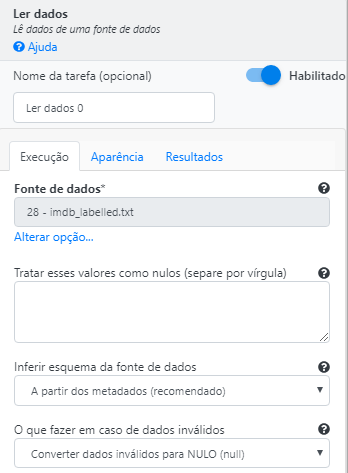
Adicione uma base de dados por meio da operação Ler dados.
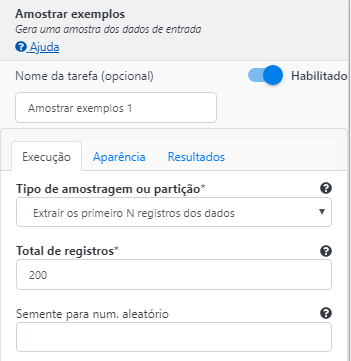
Na operação Amostrar, selecione “Extrair os primeiros N registros dos dados” como Tipo de amostragem ou partição e digite o valor “200” para o campo Total de registros.
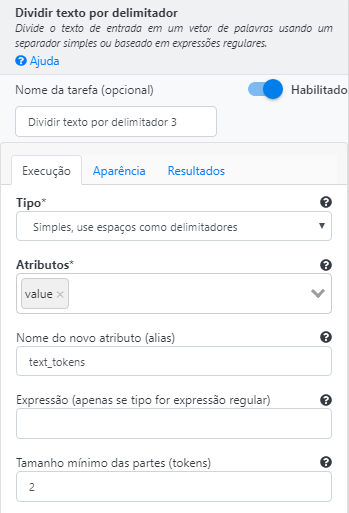
Utilize a operação Dividir texto por delimitador. Selecione a opção “Simples, use espaços como delimitador” para o campo Tipo. Preencha “value” no campo Atributos, “text_tokens” no campo Nome do novo atributo e o valor “2” no campo Tamanho mínimo das partes.
Utilize a operação Remover palavras comuns. Preencha “text_tokens” no campo Atributos e selecione “inglês” no campo Idioma (opcional).
Utilize a operação Contar frequência dos termos. Selecione “text_tokens2” para o campo Atributo. Preencha “text_vector” no campo Nome do novo atributo. Selecione a opção “Contar a frequência do termo” no campo Tipo. Preencha o valor “10000” no campo Tamanho do vocabulário. Preencha o valor “1” para ambos os cambpos Frequência mínima de documento e Frequência Mínima do Termo.
Utilize a operação Latent Dirichlet Allocation (LDA). Selecione “text_vector” para o campo Atributo(s) previsor(es). Preencha “prediction” no campo Atributo com a predição (novo). Selecione a opção “Otimizador EM (Expectation Maximization)” para o campo Otimizador. Preencha o valor “10” no campo Número de tópicos (K). Preencha o valor “200” para o campo Número máximo de iterações.
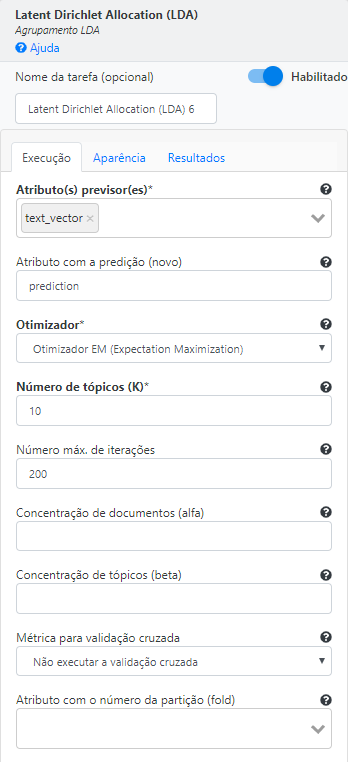
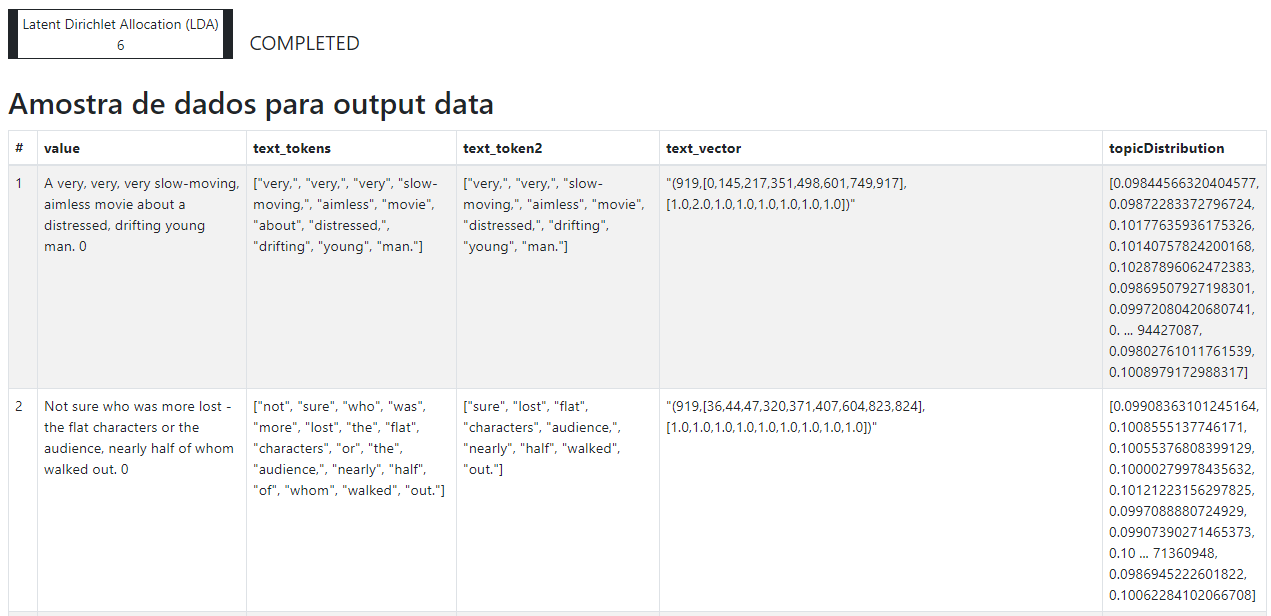
Execute o fluxo e visualize os resultados.
Dúvidas e/ou sugestões envie um e-mail para suporte@lemonade.org.br