Criação de um experimento preditivo
Agora que já finalizamos a apresentação básica da criação de um fluxo de trabalho, podemos aprofundar um pouco mais sobre a manipulação de fluxos, criando o nosso primeiro experimento completo. Neste experimento utilizaremos algoritmos de aprendizado de máquina para avaliar e prever o comportamento dos atributos da base de dados que carregamos anteriormente na Seção 2.
Ao final, construiremos um modelo, baseado em algoritmos capazes de analisar um conjunto de atributos e instâncias selecionados e, com isso, possivelmente encontrar padrões de comportamento nessa base de dados
A base de dados Iris foi utilizada por R.A. Fisher em 1936 no clássico artigo The Use of Multiple Measurements in Taxonomic Problems. Essa base é modelada como um problema de classificação. Em um problema de classificação, a ideia é predizer a natureza desconhecida de uma observação (instância ou exemplo) baseando-se atributos previsores (características ou variáveis) que a descrevem, ou seja, uma coleção de medidas numéricas e/ou categóricas. A natureza desconhecida de uma observação é chamada de classe (rótulo, class ou label).
Por exemplo, a base de dados Iris é composta por três espécies de flores do gênero Iris: Iris Setosa, Iris Versicolour ou Iris Virginica. Essas três espécies são a classe dessa base de dados. Além disso, cada espécie de flor Iris é composta por 50 observações, e por quatro atributos, que descrevem cada flor: Sepal Length: Comprimento da sépala em cm; Sepal Width: Largura da sépala em cm; Petal Length: Comprimento da pétala em cm, Petal Width: Largura da pétala em cm.
O que deseja-se para um algoritmo de classificação é predizer uma nova espécie de Iris, dentre as três possíveis (ris Setosa, Iris Versicolour ou Iris Virginica), dado esses quatro atributos.
Todo o processo de criação de um modelo que se baseie em aprendizado de máquina se inicia pelo estudo (estatístico) da base de dados. Precisamos conhecer melhor os dados para conseguir formalizar quais perguntas o nosso modelo será capaz de responder.
A análise estatística sobre esses dados nos ajuda a compreender o relacionamentos entre os atributos e inferir informações sobre a base de dados. Assim, iremos à plataforma Lemonade para criar um fluxo de trabalho e adicionar algumas operações para gerar um sumário estatístico da base. Vamos criar um fluxo de trabalho com o nome “Meu primeiro experimento preditivo”.
Para sumarizar a base de dados, precisamos inicialmente ler os dados utilizando a operação Ler dados. Ela está relacionada entre as opções encontradas na categoria de operações Entrada e saída. Nesta categoria, encontramos todas as operações de entrada e saída das bases de dados e dos modelos. Para utilizarmos a operação de leitura, basta selecioná-la na aba de operações e arrastá-la para o grid. O mesmo deve ser feito com a operação Sumário estatístico, ligando as duas ao arrastar o plug de saída da operação Ler dados para o plug de entrada da operação Sumário estatístico, como indicado na imagem.

Ao clicar na operação Ler dados, a ferramenta disponibiliza uma aba a direita com todos os parâmetros de configuração. No campo Fonte de dados, selecione a base “iris.csv”, que foi carregada da mesma forma que na Seção 2.
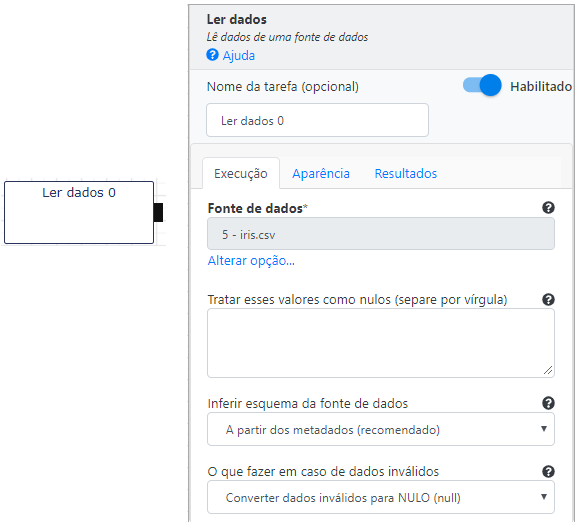
A aba Execução contém os parâmetros de execução descritos a seguir.
- Tratar esse valores como nulos (separe por vírgula): Esta funcionalidade é utilizada quando se é necessário corrigir/eliminar atributos do fluxo de dados;
- Inferir esquema da fonte de dados: Determina como os atributos serão inferidos pela operação. É recomendado que os atributos sejam inferidos da base de dados;
- O que fazer em caso de dados inválidos: Convert Invalid data to NULL. Determina como os atributos inválidos devem ser tratados. Neste caso definimos que todos os dados inválidos serão convertidos para NULO automaticamente;
A aba Aparência nos permite mudar as cores das caixas das operação e inserir comentários. A aba Resultados nos permite manipular quais informações serão exibidas após a execução. Para este caso selecionamos as opções:
- Exibir amostras das saídas: permite visualizar uma prévia dos dados;
- Exibir esquema/dicionário das saídas**: exibe o formato dos dado de cada atributo;
- Exibir relatórios textuais (se disponíveis): exibe relatórios de texto caso disponíveis. Esses relatórios geralmente estão vinculados a resultados de análise de algoritmos;
- Exibir relatórios e gráficos (se disponíveis): exibe imagens e/ou gráficos quando disponíveis;
Agora é o instante de definir a operação para o cálculo do Sumário Estatístico da base. Ela se encontra no conjunto Visualização de Dados.
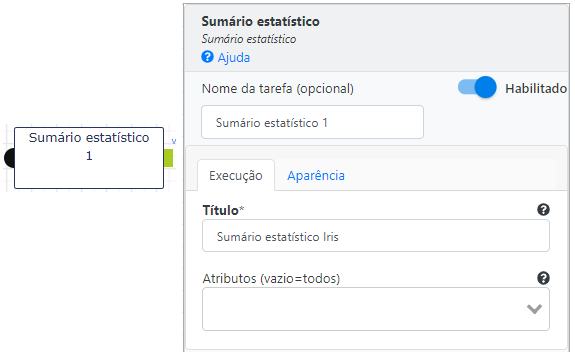
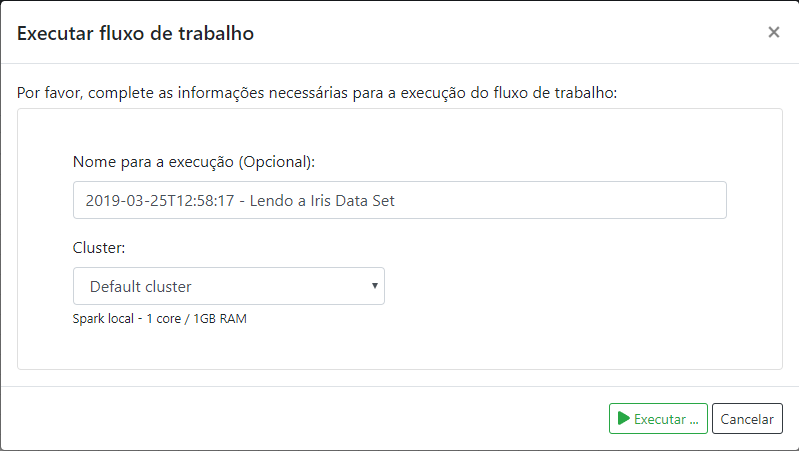
O único parâmetro que vamos definir é o nome da tabela de sumário. Ao executar o fluxo temos o resultado.
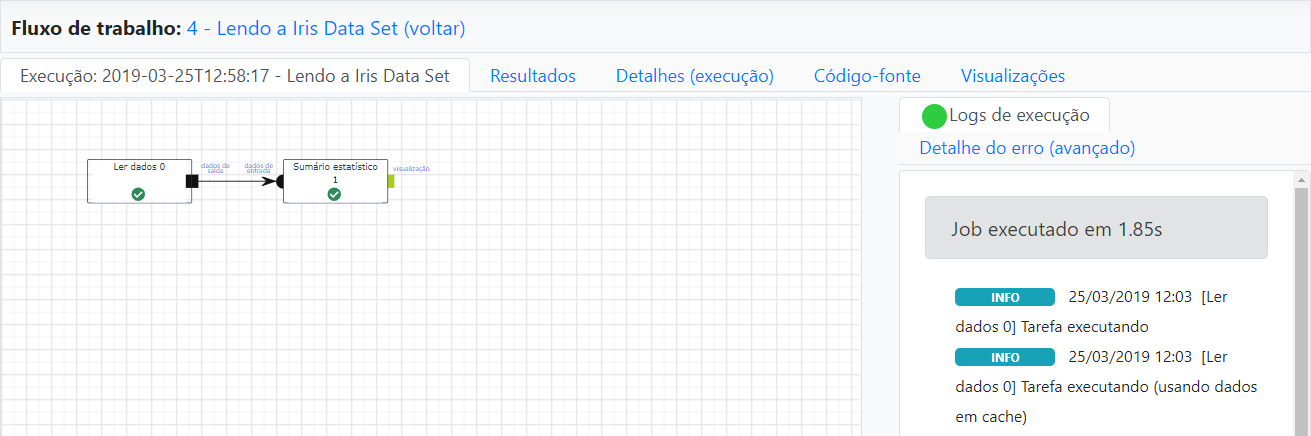
Na aba visualizações, temos o resultado do Sumário estatístico:
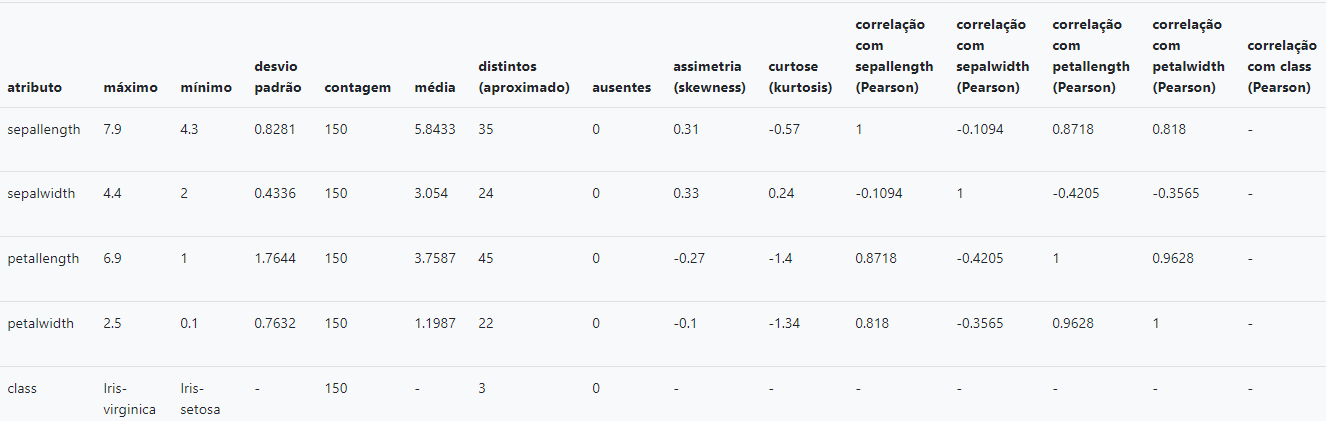
O principal objetivo dessa etapa é fazer com que o usuário conheça os atributos da sua base e seja capaz fazer perguntas que nosso modelo tenha condições de responder. Ele será capaz de analisar as características e relacionamentos dos diferentes atributos e predizer um resultado. Agora que já definimos um pouco da teoria, vamos direto à análise da base Íris.
O que nós podemos tentar predizer?
A partir da análise dos atributos de cada registro (linha) podemos predizer a qual espécie aquele exemplar pertence. Logo, podemos concluir que o comprimento e a largura da pétala e sépala são os atributos, enquanto a classe da espécie é o rótulo.
No Lemonade, todas as operações relacionadas ao aprendizado de máquinas estão baseadas no Apache Spark Framework, logo precisamos formatar as operações do fluxo de forma que os parâmetros se adequem a seguinte estrutura de dados.
Portanto a próxima etapa do nosso experimento consiste no treinamento e avaliação de um modelo de classificação. Cada modelo é formado pela estrutura de dados e um algoritmo de aprendizado de máquina. Ao final, o nosso modelo será avaliado utilizando um processo de validação cruzada ou Cross-validation ML process.
Extração de atributos (Extract features)
Para construir um modelo de classificação, primeiramente precisamos extrair todos os atributos que mais contribuem para classificação dos dados.
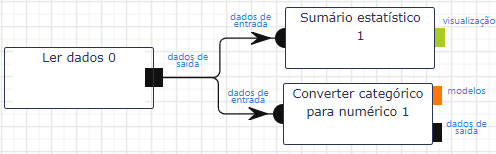
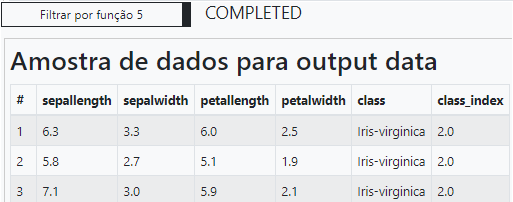
Na base de dados Iris, a espécie das flores é rotulada (labeled) em 3 classes: iris-virginica, iris-setosa, iris-versicolor, enquanto os atributos são definidas pelos tamanho e largura da sépala e da pétala: sepal length, sepal width, petal length, petal width.\
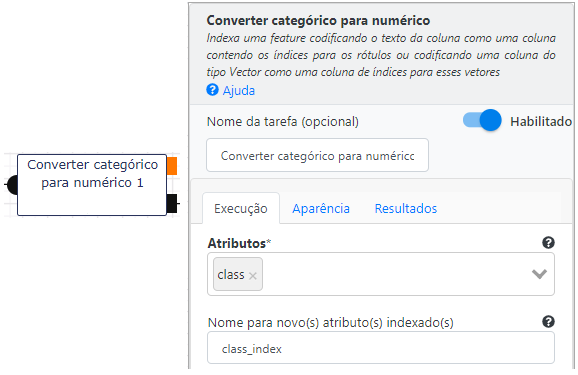
Para que a classe ou espécie possa ser utilizada pelos algoritmos de machine learning, precisamos inicialmente converter os valores categóricos das 3 classes em um valor numérico. Os algoritmos sempre recebem como parâmetros vetores numéricos. Utilizaremos a operação de Converter categórico para numérico no grupo de Pré-processamento de dados, para converter o atributo class. O atributo resultante terá o nome class_index.
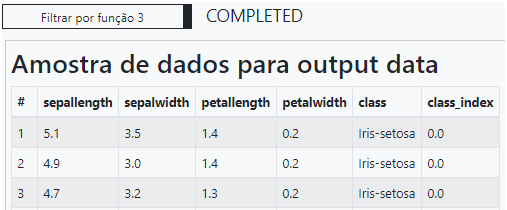
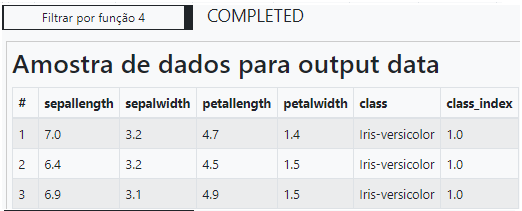
Podemos utilizar uma operação de transformação nos dados filtrando os valores de label em cada uma das classes presentes na base. Vale observar que é apenas uma operação de manipulação e não caracteriza o modelo de treinamento e avaliação que desejamos criar. Sua finalidade é apenas a visualização dos atributos criados na etapa de extração de atributos. A classe “Iris-setosa” recebeu o valor 0 como class_index. A classe “Iris-versicolor” recebeu o valor 1 como class_index. A classe “Iris-virginica” recebeu o valor 2 como class_index.
Treinamento do Modelo (Train Model)
Depois da extração dos atributos da base de dados entramos na fase do treinamento do modelo. Para treinar, precisamos inicialmente dividir os dados em duas partes: uma parte vai ser destinada ao treinamento (conjunto de treinamento) e outra a sua avaliação (conjunto de teste).
Fluxo do conjunto de treinamento
Nessa parte do workflow, a operação Dividir (na seção de Transformação de Dados), será ligada à saída da operação Converter categórico para numérico.
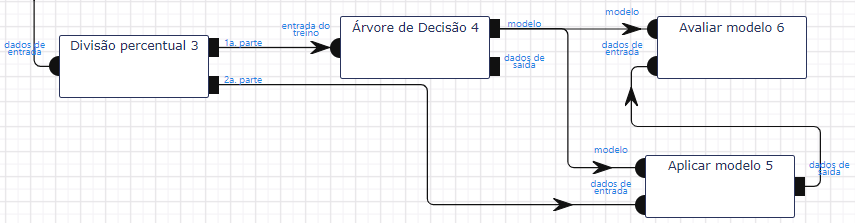
O treinamento ocorre a partir de um algoritmo de análise. No nosso exemplo utilizaremos o algoritmo de classificação Árvore de Decisão.
Além do fluxo completo, segue abaixo cada uma das operações com seus parâmetros principais.
Divisão Percentual
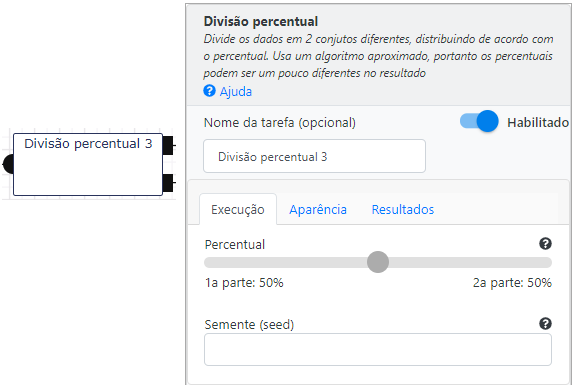
Divide o fluxo de dados em duas partes que podem ser definidas movendo o indicador de peso. No nosso exemplo separamos 50% dos dados para treinamento e 50% para testes.
Árvore de Decisão
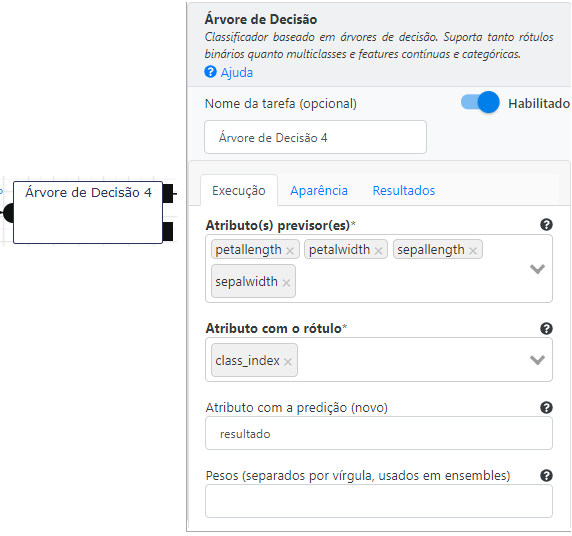
Selecionamos todos os atributos mencionados na etapa anterior como parâmetros de entrada. O objetivo da operação é permitir o processo de treinamento, criando o modelo de classificação. A saída do modelo é o resultado de predição do modelo armazenado na variável resultado. Como este tutorial é destinado a usuários iniciantes não entraremos em detalhes quanto ao significado dos outros parâmetros utilizados neste classificador. Utilizamos sua versão padrão, sem modificar os parâmetros iniciais. Informações mais aprofundadas podem ser encontradas no manual das operações de classificação.
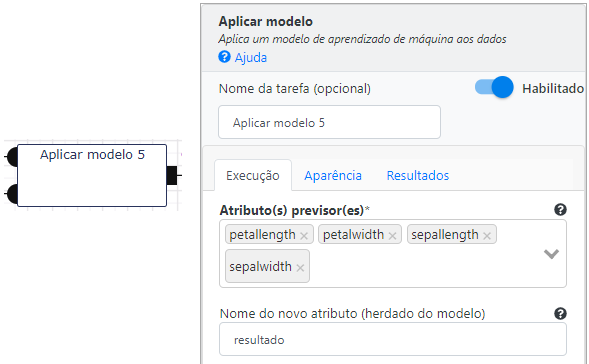
Aplicar Modelo
Após a criação e o treinamento do modelo é o momento de aplicar o modelo ao restante dos dados da base. Para isso, utilizaremos a operação Aplicar modelo, pertencente à seção de Modelo e Avaliação. O nosso objetivo é realizar a predição do resultado para esta parte dos dados e posteriormente avaliar o resultado. Os parâmetros que utilizamos são os atributos petal length, petal width, sepal length e sepal width, e a variável resultado da predição (resultado).
Avaliação de modelo (Evaluate model)
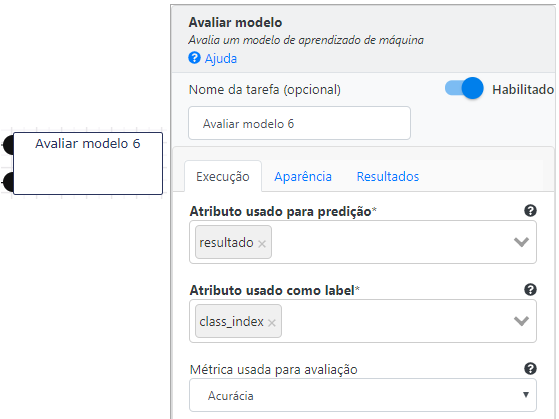
Será que um algoritmo de classificação que use árvore de decisão foi a melhor opção para este volume de dados? É o que analisaremos na próxima etapa. Para finalizar o nosso experimento precisamos avaliar o nosso modelo. Para isso basta adicionar a operação Avaliar Modelo nas saídas das operações Árvore de decisão e Aplicar Modelo. O papel dessa operação é comparar os resultados do modelo com os valores originais, e apresentar uma nota (score) de aproveitamento. Esta nota varia de acordo com o tipo de métrica usada na avaliação do modelo. Para o exemplo em questão utilizamos accuracy, aplicada para atributos multiclasse. Não entraremos em detalhes na especificação dos atributos da operação. Maiores informações podem ser encontradas nas documentações das operações.
Avaliar Modelo
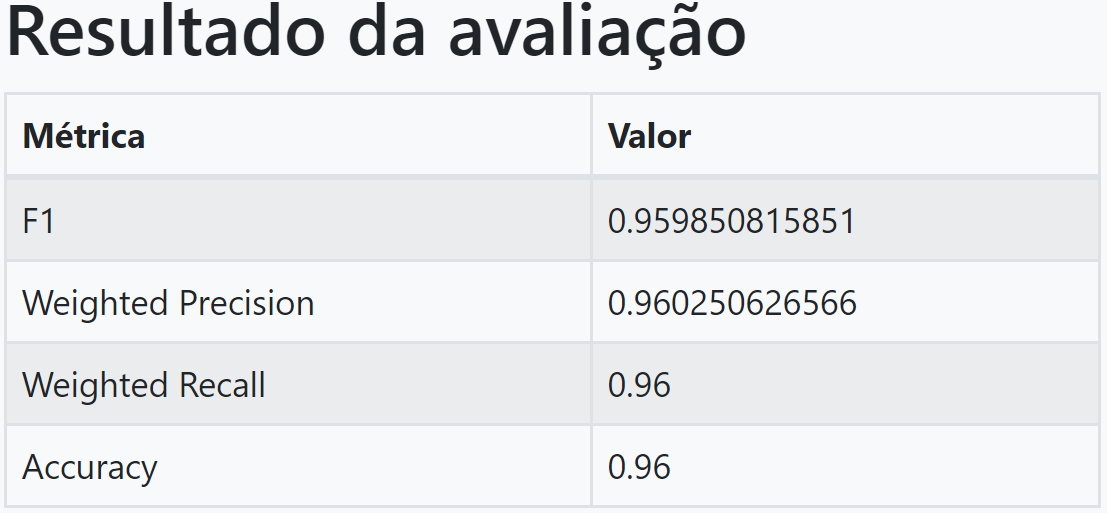
Após a execução, podemos acessar os resultados da avaliação do modelo na aba Resultados. Na avaliação da acurácia do algoritmo, encontrando o valor 0.96. A medida de acurácia geralmente é o ponto de partida para a análise de um modelo. Ela equivale ao número de predições corretas dividida pelo número total de predições realizadas. Se calcularmos a porcentagem da acurácia temos 96%.
Para completar a avaliação e evitar qualquer ambiguidade, visto que diferentes algoritmos podem apresentar valores bem diversos de acurácia, a análise dos resultados por meio da matriz de confusão é uma alternativa.
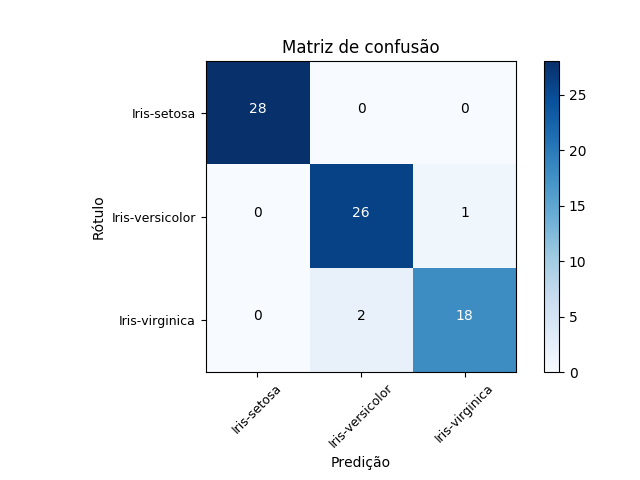
Avaliando a matriz de confusão, gerada pela ferramenta, podemos verificar que o algoritmo que escolhemos para o modelo consegue um excelente resultado em predizer o comportamento da base teste. A quantidade de verdadeiros positivos foi muito superior em relação à quantidade de falsos negativos na detecção das espécies, comprovando o valor encontrado de acurácia na tabela anterior. Deixo com você a tarefa de realizar este mesmo experimento com outros algoritmos, e avaliando a acurácia dos mesmos em busca de um modelo ainda mais acertado. Há de se considerar a aleatoriedade em execuções de Aprendizado de Máquina, em todas as fases, seja na coleta dos dados, nos algoritmos em si ou nas amostras para o modelo e testes. Isso resulta em números de acurácia diferentes, mesmo com o mesmo conjunto de dados e modelo, em execuções diferentes.
Criação de um painel de visualizações
O uso de visualizações dinamiza o processo de análise de uma base de dados. Com gráficos, podemos encontrar padrões, reconhecer comportamentos desconhecidos e principalmente responder nossas dúvidas ou hipóteses. Uma visualização utiliza a comunicação visual para tornar mais perceptível o significado e o valor dos atributos.
O grande desafio do analista de dados é conseguir comunicar todas as informações que conseguiu extrair de uma visualização para seu público alvo. O objetivo do Lemonade é dar a qualquer analista a possibilidade de criar visualizações de forma simples e dinâmica, apresentando suas análises com velocidade, simplicidade e qualidade. Na figura abaixo estão os gráficos disponibilizados pelo Lemonade.
O Lemonade apresenta os seguintes tipos de visualização de dados:
Gráfico de Área (Area chart): Este tipo de gráfico é baseado no gráfico de linhas, e a área entre o eixo e a linha é comumente enfatizada com cores, texturas e hachurados. Normalmente é utilizado para representar resultados acumulados ao longo do tempo, utilizando de números e porcentagens.
Gráfico de Barras (Bar chart): Este tipo de gráfico é composto por barras retangulares proporcionais aos valores que elas representam, e podem ser plotadas vertical ou horizontalmente. É utilizado para representar dados categóricos, isto é, um agrupamento de dados dividido em grupos discretos, como meses do ano.
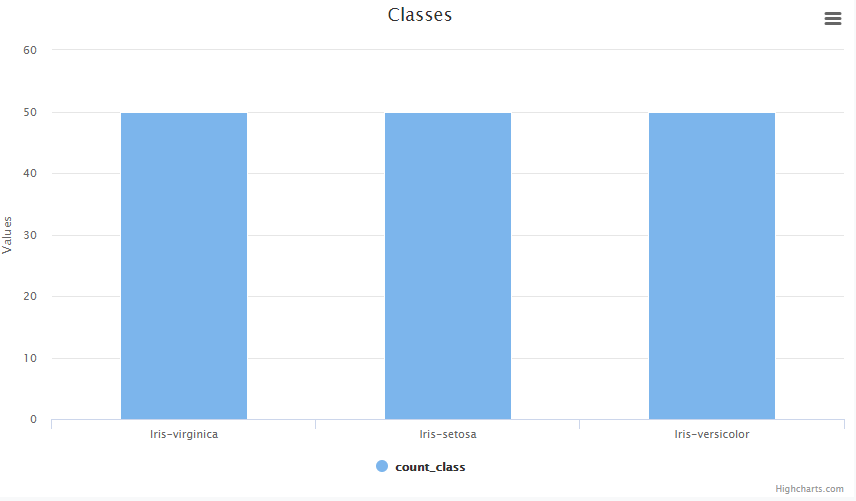
Gráfico de Dispersão (Scatter plot chart): Este tipo de gráfico utiliza de coordenadas cartesianas para exibir, tipicamente, valores de duas variáveis em um conjunto de dados. Se os pontos forem coloridos, é possível a exibição de mais uma variável.
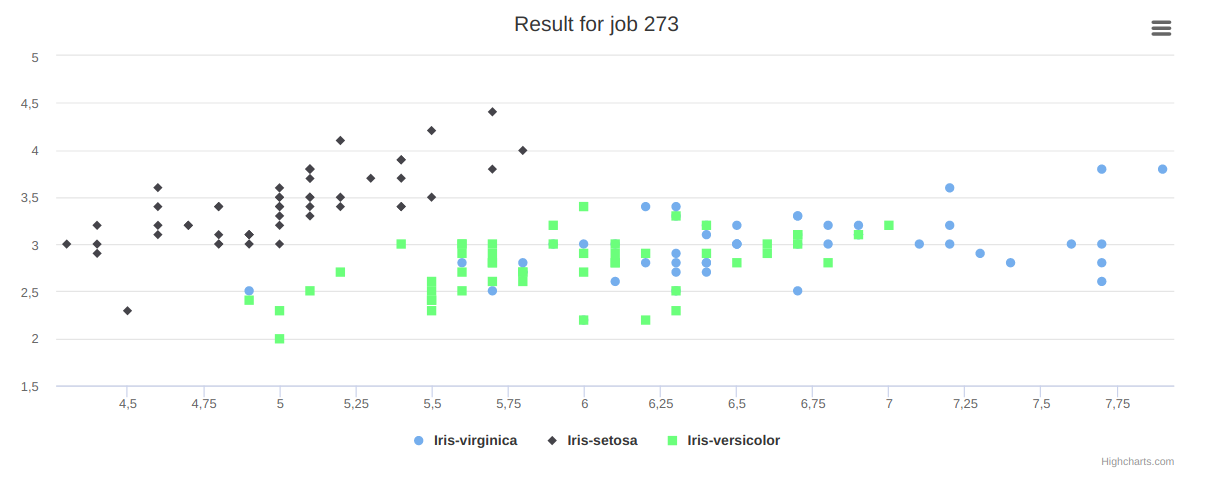
Gráfico de Linha (Line chart): Este tipo de gráfico consiste em uma série de pontos de dados ligados por linhas retas. É utilizado para visualizar a tendência dos dados ao longo de intervalos de tempo, e é um dos mais comuns tipos de gráficos.
Gráfico de Pizza (Pie chart): É um gráfico estatístico circular, dividido em setores para ilustrar proporção numérica entre diversos valores acerca de um tópico. Não é recomendado quando se trata de um número muito grande de setores, já que a visualização se torna confusa e pouco significativa.
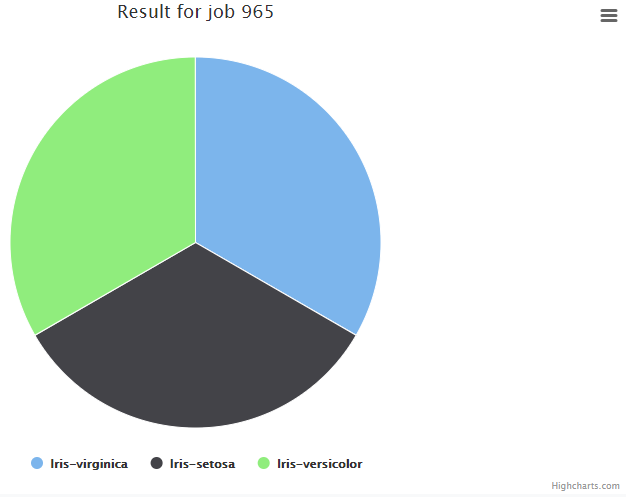
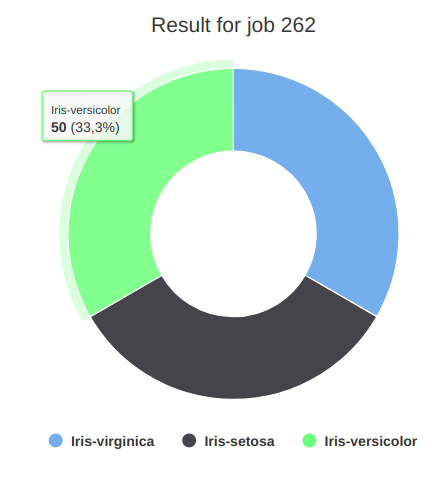
Gráfico de Rosca (Donut chart): Este tipo de gráfico é uma variante do gráfico de pizza com uma lacuna em seu centro, o que possibilita a adição de mais informações sobre os dados como um todo.
Publicar como dashboard: Pública as visualizações ligadas a ela em um quadro, chamado de Dashboard, e acessível no menu principal, à esquerda.
Sumário Estatístico: É uma tabela que contém análises estatísticas acerca dos dados trabalhados.
Visualização em mapa: Retrata os dados em um mapa, quando fornecidos dados de latitude e longitude, além de dados quantitativos.
Visualização em tabela: Uma tabela que mostra a base de dados, similar à primeira caixa da aba Resultados dos parâmetros das operações.
Utilizaremos alguns deles nos exemplos que seguirão. Mais informações podem ser encontradas nas documentações das operações.
Para tornar essa parte da documentação interessante utilizamos nos nossos exemplos a base Titanic, utilizada em umas das competições do site Kaggle: Kaggle Competition - Titanic Machine Learning from Disaster (o arquivo que utilizaremos será o de treinamento, train.csv).
Diz o site:
O naufrágio do RMS Titanic é um dos naufrágios mais famosos da história. Em 15 de abril de 1912, durante sua viagem inaugural, o Titanic afundou depois de colidir com um iceberg, matando 1502 de 2224 passageiros e tripulantes. Essa tragédia sensacional chocou a comunidade internacional e levou a melhores normas de segurança para os navios.
Uma das razões pelas quais o naufrágio levou a uma perda de vidas era que não havia botes salva-vidas suficientes para os passageiros e tripulantes. Embora houvesse algum elemento de sorte envolvido na sobrevivência do naufrágio, alguns grupos de pessoas eram mais propensos a sobreviver do que outros, como mulheres, crianças e a classe alta. Neste desafio, pedimos que você complete a análise de que tipos de pessoas provavelmente sobrevivem. Em particular, pedimos que você aplique as ferramentas de aprendizado de máquina para prever quais passageiros sobreviveram à tragédia.
Não construiremos o modelo de predição da tragédia requerido na competição, porém você pode utilizar o nosso exemplo anterior: Criando meu primeiro experimento predictivo para testar seus conhecimentos em aprendizado de máquina.
Vamos tentar tirar algumas informações interessantes dos dados e formatá-los por meio de visualizações. Para tornar o nosso processo mais dinâmico, vou deduzir que você já sabe carregar a base para o lemonade. Se ainda não sabe, volte duas seções e dê uma lida na seção de Importação de base de dados. Pode acontecer que os nomes dos atributos utilizados para o nosso exemplo sejam diferentes dos que você escolher, mas o importante é o entendimento do processo. Também vou deduzir que você sabe criar um novo workflow e já entende seu funcionamento. O formato do workflow que construiremos será o seguinte:
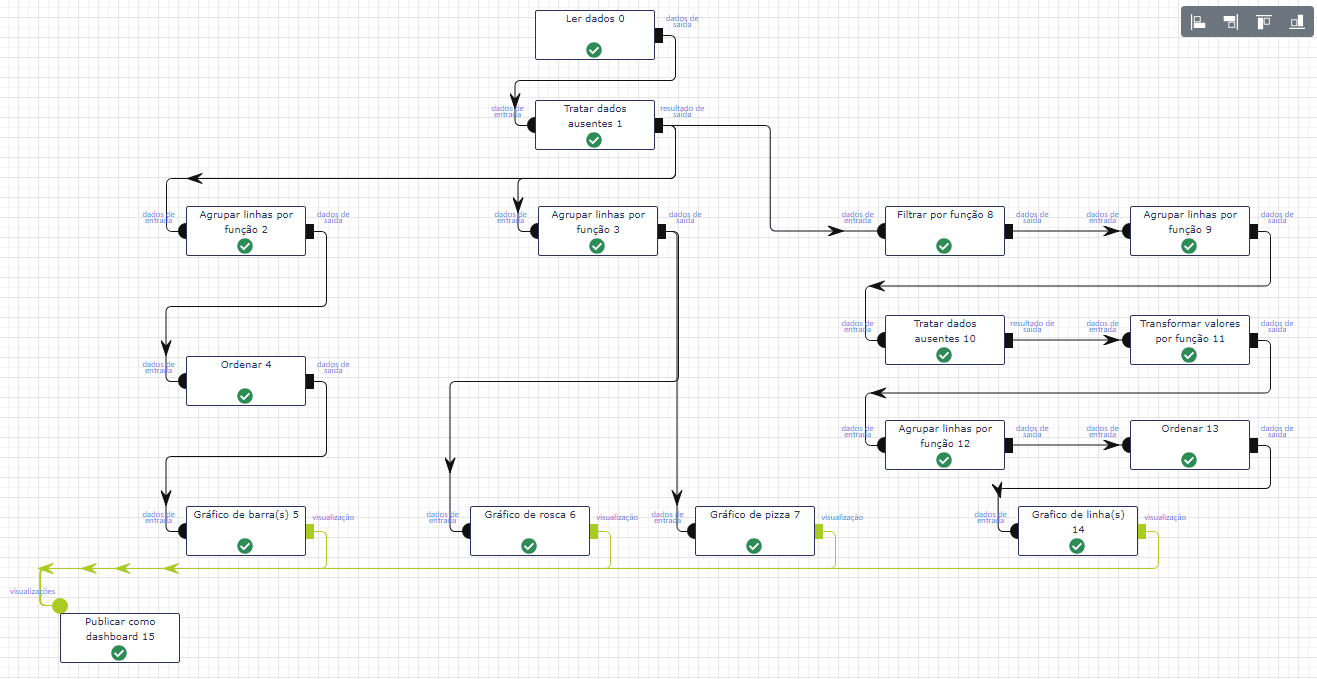
Carregamento da base e consistência dos dados
Inicialmente precisamos carregar a base que importamos. Para manter o dinamismo do nosso processo, optamos por fazer a consistência dos dados eliminando qualquer linha que apresente qualquer problema. Você pode optar por verificar os casos de erro e fazer as alterações necessárias.
Vamos dar um preview dos atributos da base para analisar a formatação dos dados (marcando a primeira caixa na aba Resultados nos Parâmetros da Tarefa).
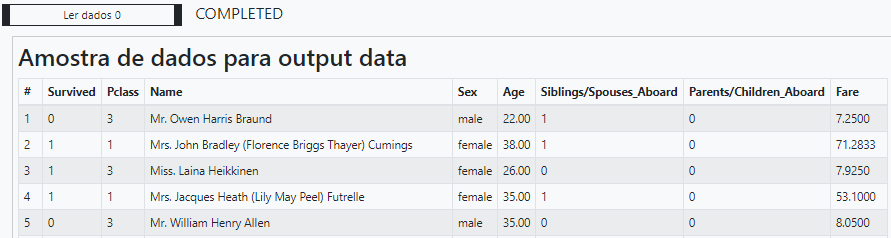
Como o objetivo dessa documentação é apenas ensinar ao usuário como criar visualizações, escolhemos por remover todas as linhas as quais os valores são nulos ou ausentes.
Vamos começar com gráficos mais simples e que exigirão menor esforço na criação do fluxo. Vamos criar um gráfico de pizza e um gráfico de rosca (donut ) que nos responda o número de sobreviventes e mortos respectivamente, para este fragmento de base.
Para gerar os gráficos, precisamos manipular os dados selecionando os atributos que vão compor os eixos. Para este exemplo, precisaremos do atributos Pclass e Survived. Vamos dar uma olhada na operação de agregação: Agrupar linhas por função. Precisamos contar os sobreviventes e mortos por cada uma das classes.
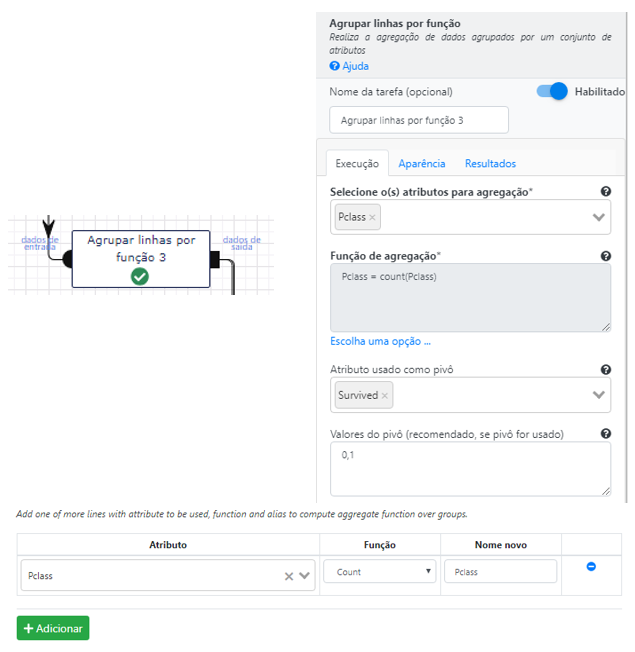
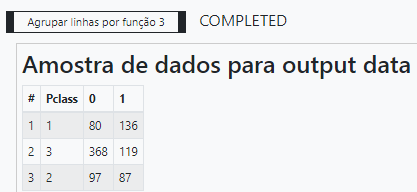
Para contar o número de sobreviventes e mortos por classe precisamos utilizar o atributo Survived como pivô, isto é os valores de Survived serão sumarizados em uma tabela agregada por classe. Isto explica porque os valores 0 e 1 foram inseridos na caixa Atributo usado como pivô. O resultado dessa operação pode ser visto em sequência no preview.
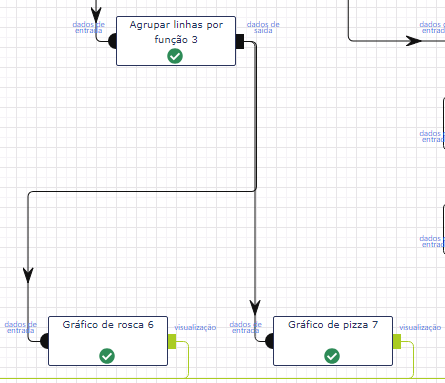
Agora basta selecionar os atributos e criar as visualizações. O gráfico de rosca vai representar o número mortos por cada classe.
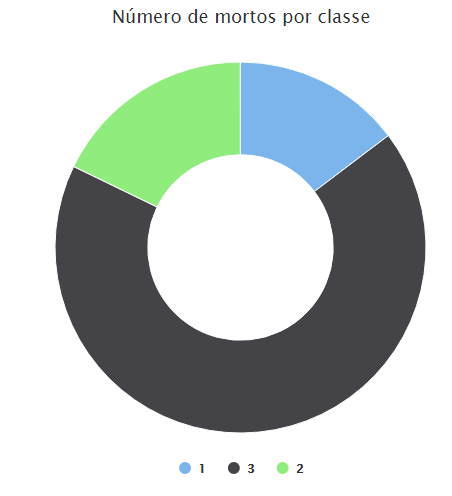
Cada cor do gráfico representa o número de mortos por classe. Deixo a você a tarefa de analisar quantos tripulantes embarcaram por classe e quais a percentagem de mortos em relação ao total. Será que os passageiros da terceira classe tiveram um número relativo de mortos maior que os passageiros da segunda e primeira classe?
Agora vamos para o gráfico de pizza, ele apresenta o número de sobreviventes por classe.
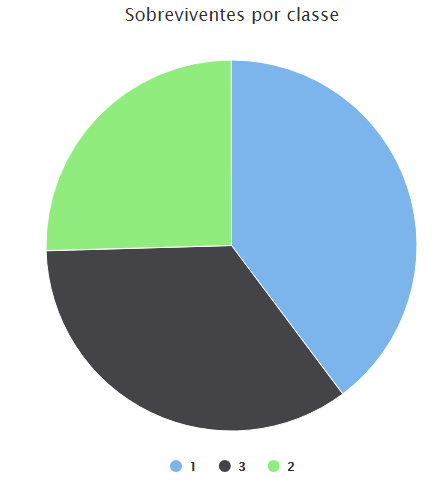
Os nossos dois últimos exemplos vão apresentar gráficos de barras e linhas respectivamente. O Lemonade permite que várias séries de dados sejam representados num mesmo gráfico permitindo que o analista seja capaz de apresentar comparações e comportamentos de mais de um grupo de informação.
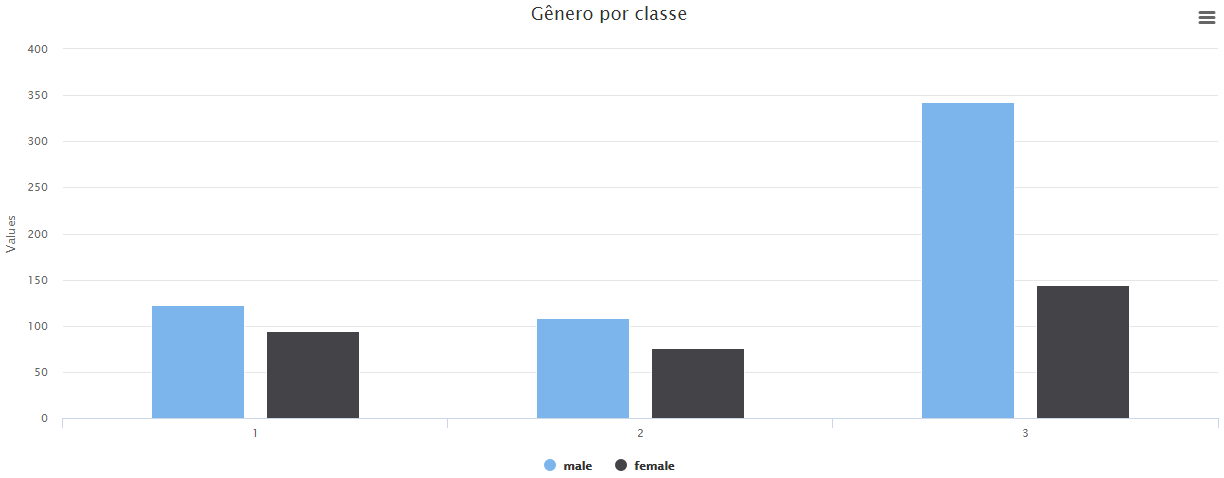
Nesse exemplo, vamos construir um gráfico de barras que apresenta o número viajantes por classe organizados por sexo. Será que nesse desastre o número relativo de mulheres e homens foram muito diferentes para cada classe? Vamos tentar achar a resposta na análise do gráfico.
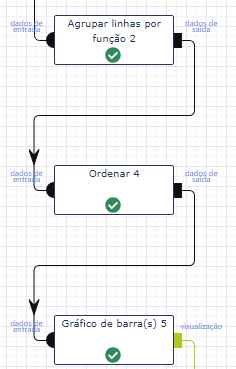
Inicialmente, vamos começar por agregar os dados pelos dois atributos que desejamos avaliar: Pclasse e Sexo. A ideia é a mesma dos gráficos anteriores, utilizaremos a operação Agrupar linhas por função: vamos agregar por classe, usar o gênero como pivot e contar a quantidade de homens e mulheres.
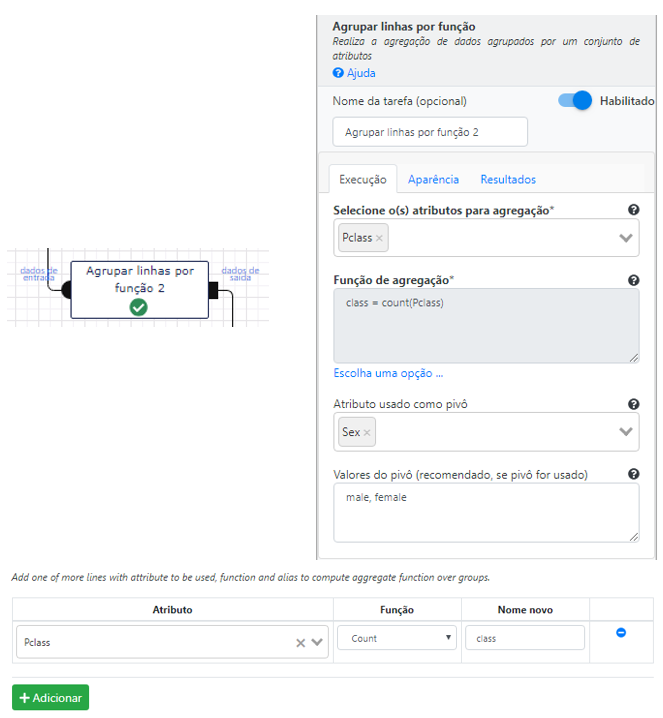
Vamos ver um preview do resultado.
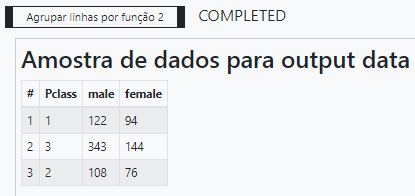
Pronto. Agora basta ordenar os resultados por classe e plotar o gráfico de barras. Para ordenar utilizamos a operação Ordenar.
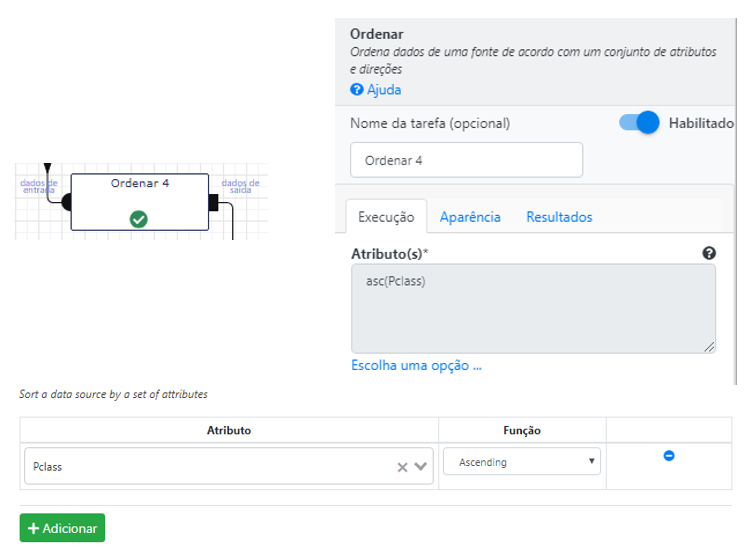
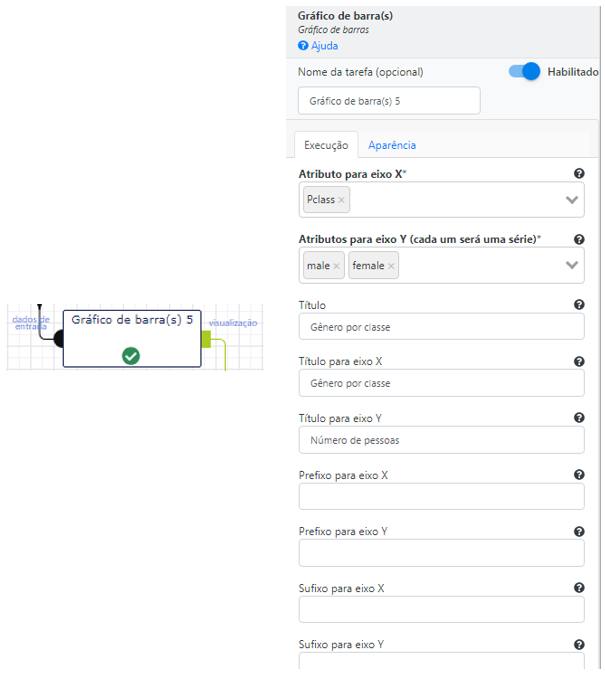
Em seguida, selecione a operação Gráfico de barras para plotar as duas séries de dados, uma para male e outra para female.
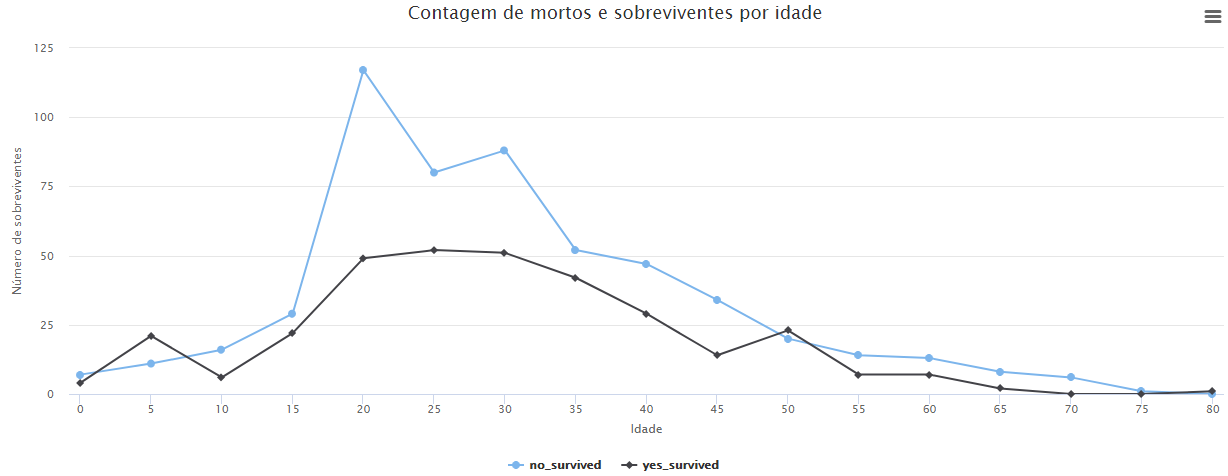
Vamos completar o nosso gráfico anterior com a seguinte análise: Quantas pessoas morreram por idade? As mortes aumentaram com o aumento da idade? Idosos e crianças foram resgatadas primeiro? É o que vamos tentar responder com nosso gráfico de linhas. Note que, este fluxo vai ser mais complexo que os exemplos anteriores, vamos definir uma idade mínima. Isso é importante para tornar a manipulação dos dados mais dinâmica e diminuir o tempo gasto em operações de tratamento dos dados.
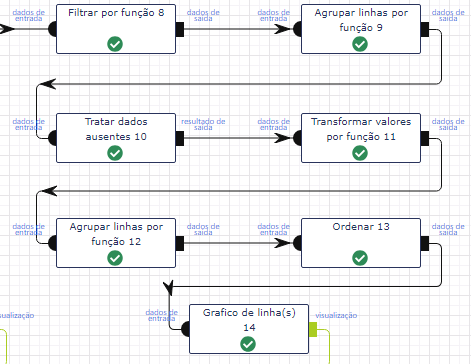
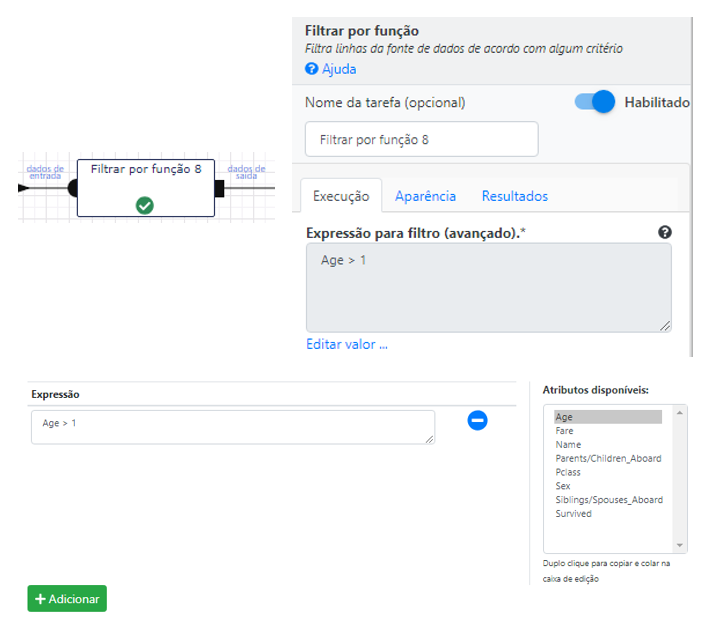
A primeira operação do nosso fluxo vai ser um filtro para idades acima de 1 ano. Para criar um filtro basta utilizar a operação Filtrar.
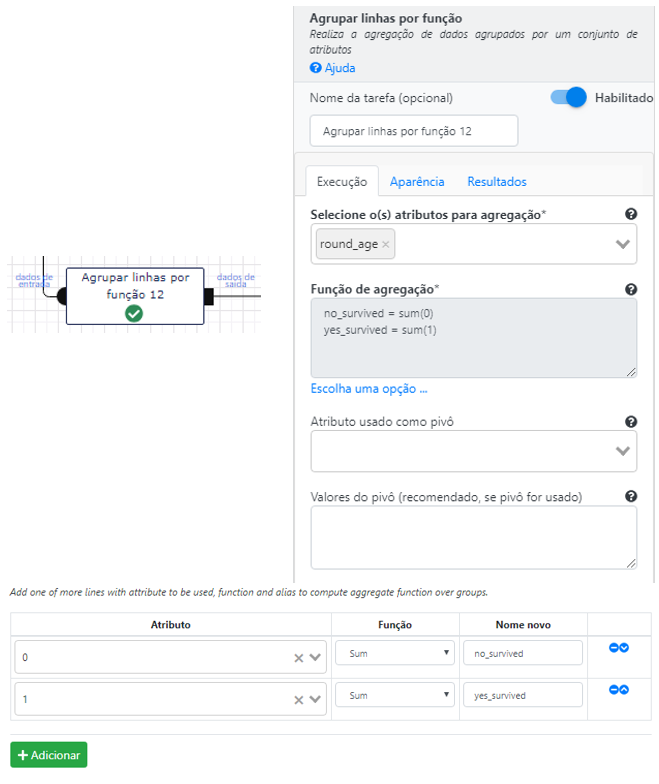
Em seguida, vamos agregar o fluxo de dados por idade e fazer o pivot pelos sobreviventes. Ao final teremos o número de mortos e sobreviventes por idade.
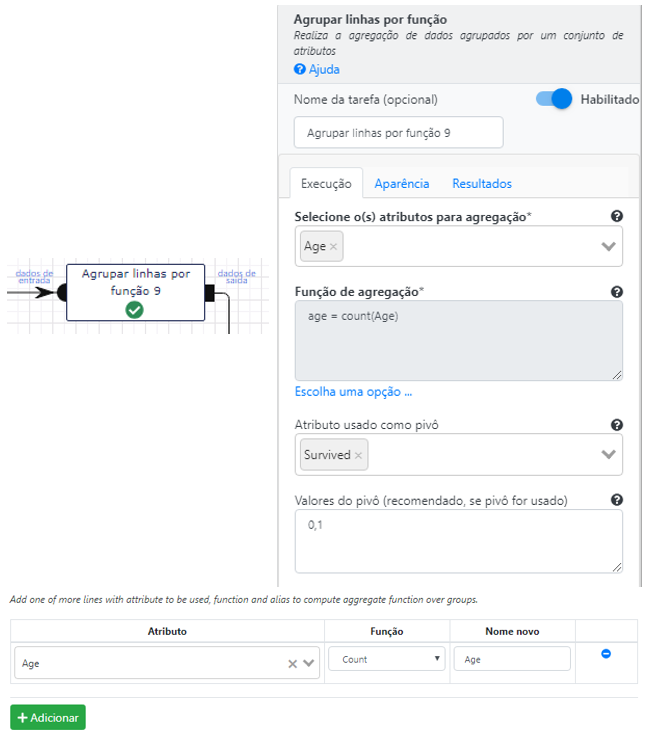
É uma boa prática de desenvolvimento sempre visualizar o resultado de uma operação complexa.
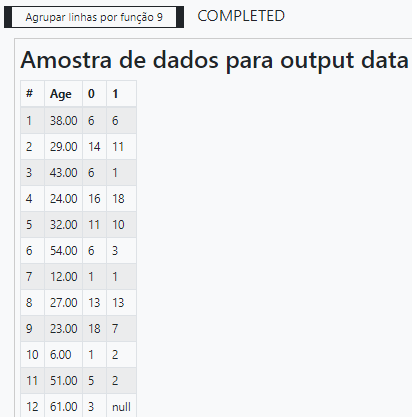
Podemos observar dois aspectos interessantes: o primeiro é que as idades não são lineares e o segundo é se o número de sobreviventes para alguma delas foi nulo. Logo precisamos realizar mais algumas transformações nesses dados antes de desenhar o nosso gráfico.
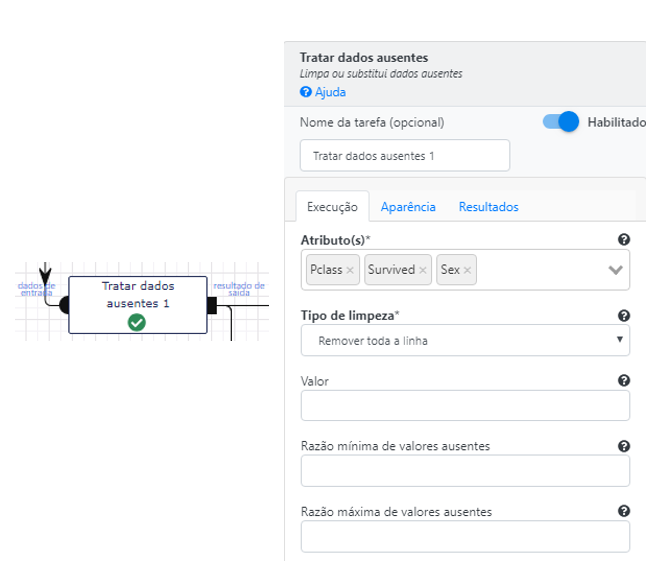
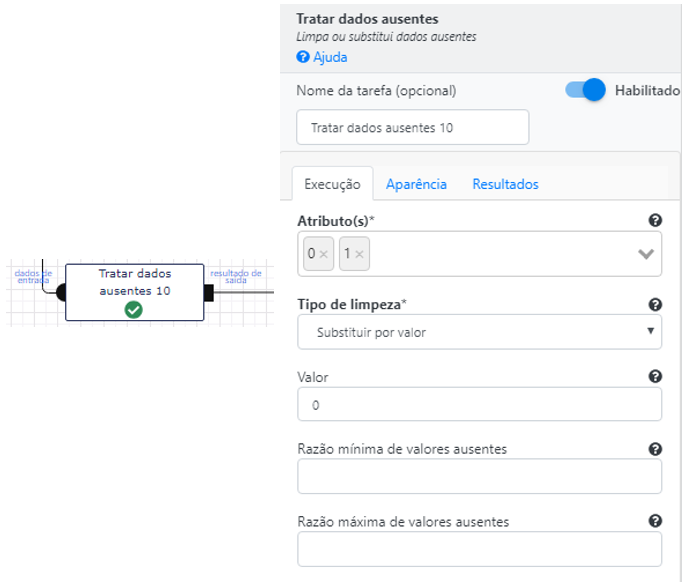
Vamos começar por substituir os valores nulos por zero. E para isso vamos utilizar a operação Tratas dados ausentes.
Uma forma de tornar a coluna das idades linear é mudar a escala para desenharmos o eixo das idades no gráfico. No nosso exemplo, vamos escolher que a idade seja formada por múltiplos de 5, isto equivale a diminuir o “zoom” de visualização das linhas. Utilizaremos uma operação nova: Transformar valores por função. Essa operação nos permite utilizar diretamente as funções da api do spark. (para ter acesso a lista das operações disponíveis, acesse a documentação completa para cada operação) Neste exemplo, utilizaremos a função round para arredondar o resultado da operação de divisão do valor absoluto de cada idade por 5 (lembre-se da nova escala), o que resulta na parte inteira do resultado da divisão a ser multiplicado por 5. (múltiplos)
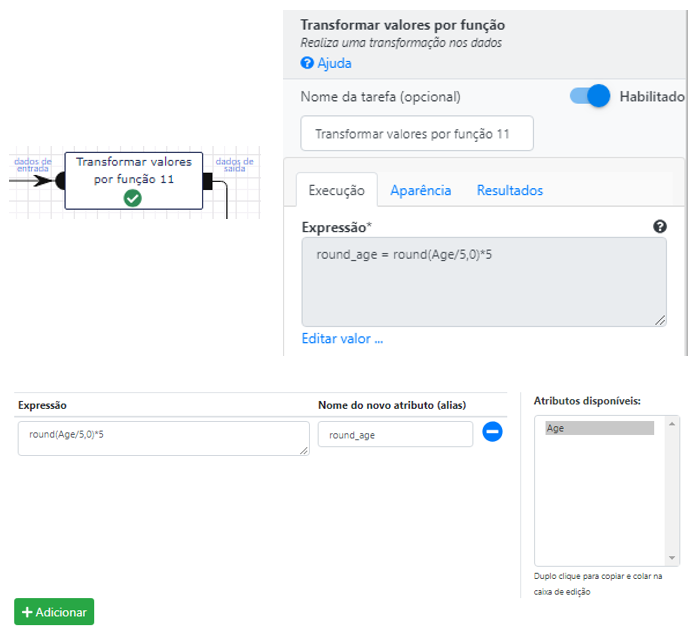
Essa parte pode ter ficado um pouco confusa. Por isso, lembre-se que podemos ver um preview dos dados e esclarecer qualquer dúvida.
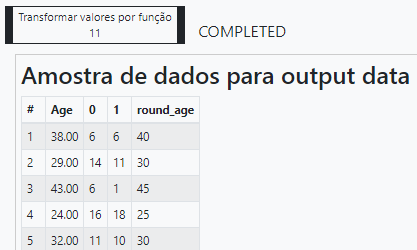
Se alteramos o valor do eixo das idades, precisamos normalizar a contagem do número de sobreviventes para cada idade absoluta. Vamos somar todos os sobreviventes de cada idade absoluta e agregar pela idade relativa na nossa nova escala.
Agora o preview de tudo o que fizemos até agora.
Vamos agora ordenar a coluna das idades.
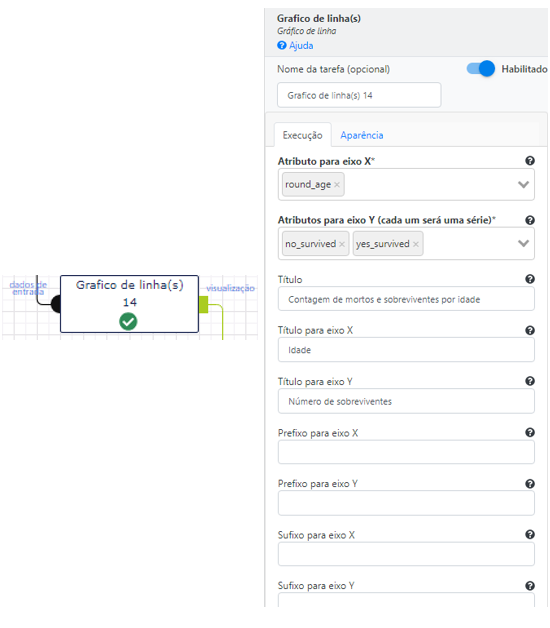
Agora basta utilizar a operação Gráfico de linha(s) para gerar o gráfico de linhas. É importante ressaltar que temos duas séries de dados para o eixo Y que correspondem ao número de mortos e sobreviventes por idade.
Para finalizar, vamos criar um painel (dashboard) e inserir nossas visualizações. Este painel vai nos permitir acessar nossas visualizações diretamente, sem a necessidade de re-executar nosso fluxo de trabalho ou acessar diretamente uma execução. Para criarmos um painel de visualizações, basta adicionar todas nossas visualizações como entrada da operação Publicar como dashboard. Seu único parâmetro é o título do painel

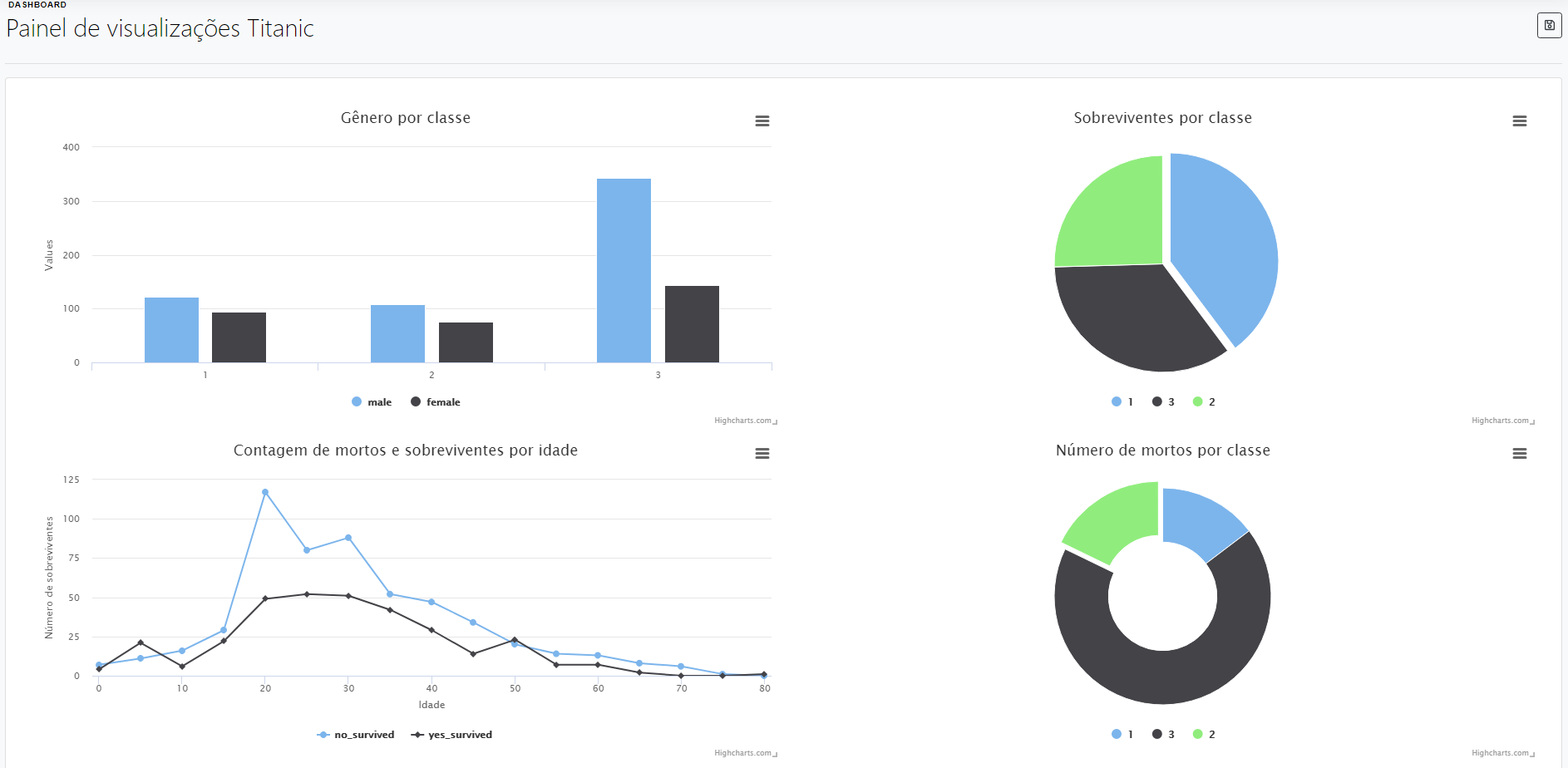
Com este painel terminamos a nossa documentação de introdução a utilização básica do Lemonade. Esperamos ter auxiliado no entendimento da ferramenta.
Dúvidas e/ou sugestões envie um e-mail para suporte@lemonade.org.br