Executar Código Python
Executa um código Python criado pelo usuário, podendo criar ou modificar uma bases de dados. É importante ressaltar que as entradas são do tipo pyspark.sql.DataFrame e as funções suportadas podem ser encontradas na documentação oficial. Com relação à criação é necessário usar a função abaixo:
createDataFrame(data, schema=None, samplingRatio=None, verifySchema=True)
A qual tem seus parâmetros detalhados na documentação do Spark.
Conectores
| Entrada | Saída |
|---|---|
| Dados a serem alterados. Podem ser referenciados como in1 e in2 | Dados criados ou alterados. Podem ser referenciados como out1 e out2 |
Tarefa
Nome da Tarefa
Aba Execução
| Parâmetro | Detalhe |
|---|---|
| Código | Código em python a ser aplicado |
Exemplo de Utilização
Objetivo: criar uma base para que o seu número de colunas seja comparado com a entrada 1, e ao final retornar a que tiver a maior quantidade de colunas. Caso as duas tenham a mesma quantidade, a entrada 1 deve ser retornada. Por fim, gerar um gráfico de dispersão para ilustrar qual foi a base retornada.
Base de Dados: Íris

Adicione uma base de dados por meio da operação Ler dados.
Adicione a operação Executar código Python. A base criada no código Python será a mesma da entrada, porém com apenas as 5 primeiras linhas, sendo fácil de identificar qual foi retornada pelo número de pontos no gráfico gerado. Portanto, adicione o código abaixo no campo Código:
#### # Write your Python code here # Inputs are available as in1 and in2, outputs are out1 and out2 data = [ [5.1,3.5,1.4,0.2,"Iris-setosa"], [4.9,3.0,1.4,0.2,"Iris-setosa"], [4.7,3.2,1.3,0.2,"Iris-setosa"], [4.6,3.1,1.5,0.2,"Iris-setosa"], [5.0,3.6,1.4,0.2,"Iris-setosa"] ] names = ["Sepal_length","Sepal_width","Petal_length","Petal_width","Species"] df = createDataFrame(data, names) if len(in1.columns) <= len(df.columns): out1 = in1 else: out1 = df ####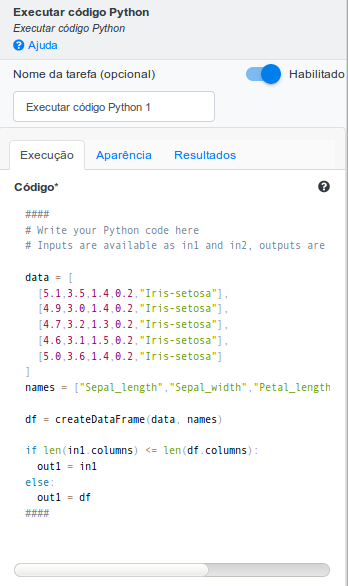
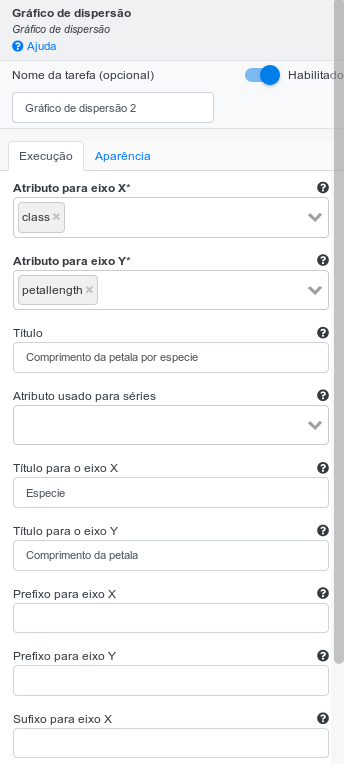
Adicione a operação Gráfico de dispersão. Utilizando “class” como Atributo para o eixo X e “Petallength” como Atributo para o eixo Y. Preencha “Comprimento da pétala por espécie” no campo Título, “Espécie” no campo Título para o eixo X e “Comprimento da pétala” no campo Título para o eixo Y.
Execute o fluxo e visualize o resultado
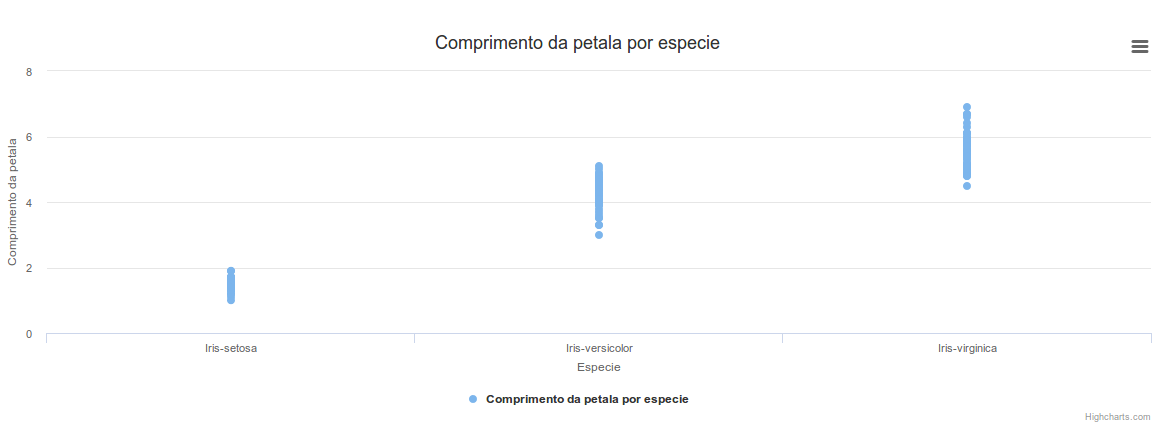
O gráfico mostra que a base retornada foi a de entrada por ter mais de 5 pontos. Esse era o resultado esperado, uma vez que ao ter o mesmo número de colunas a entrada é retornada.Para validar que a base criada pelo código é retornada se ela tiver mais colunas, é preciso alterar o que foi escrito no passo 2 e adicionar uma coluna de numeração de linhas como mostrado abaixo:
#### # Write your Python code here # Inputs are available as in1 and in2, outputs are out1 and out2 data = [ [0,5.1,3.5,1.4,0.2,"Iris-setosa"], [1,4.9,3.0,1.4,0.2,"Iris-setosa"], [2,4.7,3.2,1.3,0.2,"Iris-setosa"], [3,4.6,3.1,1.5,0.2,"Iris-setosa"], [4,5.0,3.6,1.4,0.2,"Iris-setosa"] ] names = ["Line","Sepal_length","Sepal_width","Petal_length","Petal_width","Species"] df = createDataFrame(data, names) if len(in1.columns) >= len(df.columns): out1 = in1 else: out1 = df ####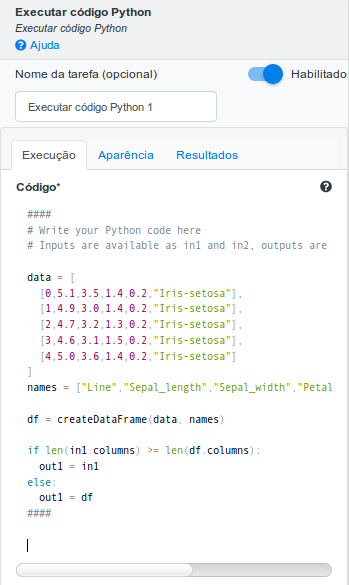
Execute o fluxo novamente e visualize o resultado.
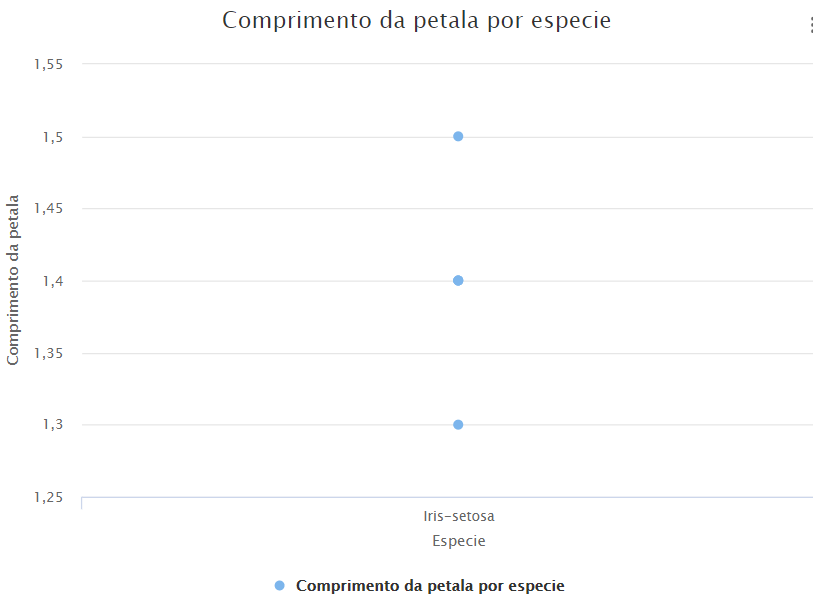
O gráfico mostra que a base retornada foi realmente a gerada pelo código por ter menos de 5 pontos.
Dúvidas e/ou sugestões envie um e-mail para suporte@lemonade.org.br